简介
关于如何使用 Git 的使用说明与学习记录。来源是一个很有意思的 Git 可视化教程:https://learngitbranching.js.org/?locale=zh_CN (Github 入口)
教程有很清晰的可视化界面可以看到各种命令的执行变化,推荐初学者跟着做一遍哦~
- git 文档:https://git-scm.com/doc
- 也可以在命令行输入
git --help查看帮助信息
工作中使用 git 进行协作是很常见的操作,由于学校中可能很少接触多人合作,所以关于 git 的使用可能不太熟悉,也为此导致代码中出现了不少 bug,又恰巧遇到一个很棒的 git 可视化教程,于是认真学习一遍以避免 git 的使用中导致的 bug.
基础篇
Commit
1 | 提交代码 |
Git 仓库中的提交记录保存的是你的目录下所有文件的快照,就像是把整个目录复制,然后再粘贴一样,但比复制粘贴优雅许多!
Git 希望提交记录尽可能地轻量,因此在你每次进行提交时,它并不会盲目地复制整个目录。条件允许的情况下,它会将当前版本与仓库中的上一个版本进行对比,并把所有的差异打包到一起作为一个提交记录。
Git 还保存了提交的历史记录。这也是为什么大多数提交记录的上面都有 parent 节点的原因 —— 我们会在图示中用箭头来表示这种关系。对于项目组的成员来说,维护提交历史对大家都有好处。
Branch
Branch 即分支,分支允许开发者在主线(master 或 main 分支)之外独立开发新功能或修复错误,而不会干扰主线的稳定性和完整性。每个分支都有自己的提交历史,这使得多个开发者可以并行工作,而不会相互干扰。
1 | 创建一个新的分支 |
Git 的分支也非常轻量。它们只是简单地指向某个提交纪录 —— 仅此而已。
即使创建再多的分支也不会造成储存或内存上的开销,并且按逻辑分解工作到不同的分支要比维护那些特别臃肿的分支简单多了。
在将分支和提交记录结合起来后,我们会看到两者如何协作。现在只要记住使用分支其实就相当于在说:“我想基于这个提交以及它所有的 parent 提交进行新的工作。”
1 | 合并分支 |
在 Git 中合并两个分支时会产生一个特殊的提交记录,它有两个 parent 节点。翻译成自然语言相当于:“我要把这两个 parent 节点本身及它们所有的祖先都包含进来。”
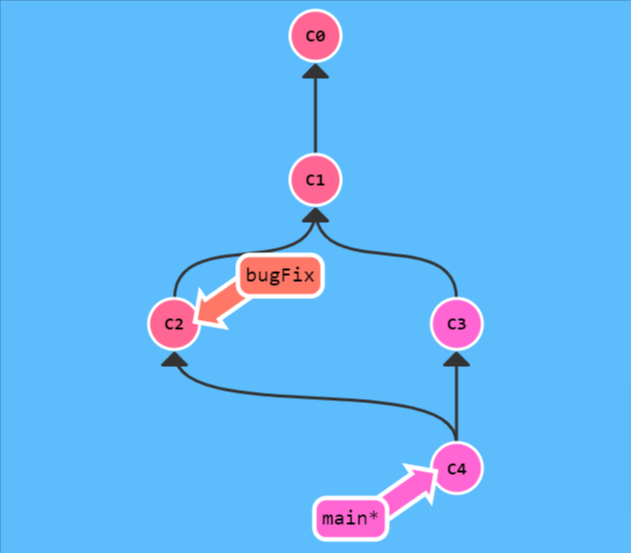
如图,merge 将 bugFix 合并到
main, 会产生一个新的提交记录,包含两个分支的提交记录。
1 | 合并分支 |
第二种合并分支的方法是 git rebase。Rebase
实际上就是取出一系列的提交记录,“复制”它们,然后在另外一个地方逐个的放下去。
Rebase 的优势就是可以创造更线性的提交历史,这听上去有些难以理解。如果只允许使用 Rebase 的话,代码库的提交历史将会变得异常清晰。
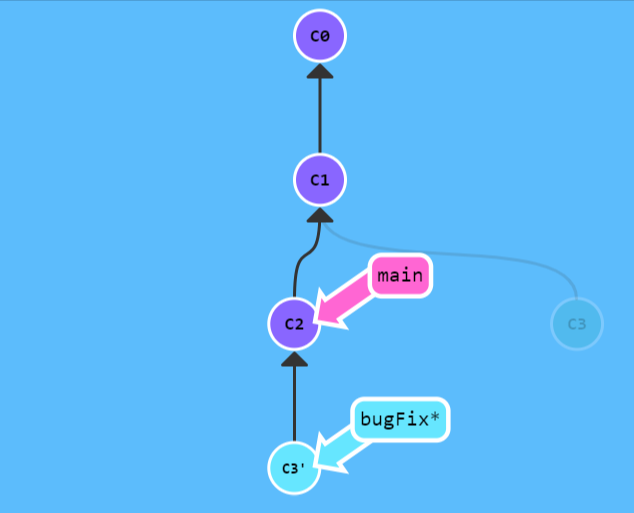
如图,rebase 将 main 合并到
bugFix, (当前分支是
bugFix),bugFix 的记录被复制到
main 的后面。
高级篇
HEAD
HEAD 是一个对当前所在分支的符号引用 —— 也就是指向你正在其基础上进行工作的提交记录。
HEAD 总是指向当前分支上最近一次提交记录。大多数修改提交树的 Git 命令都是从改变 HEAD 的指向开始的。
HEAD 通常情况下是指向分支名的(如 bugFix)。在你提交时,改变了 bugFix 的状态,这一变化通过 HEAD 变得可见。
1 | 查看 HEAD 指向 |
分离的 HEAD 就是让其指向了某个具体的提交记录而不是分支名。 HEAD
指向分支时:HEAD -> main -> C1, main
是分支而 C1 是提交记录。 分离的 HEAD 即使用
git checkout C1 使其指向 C1, 此时 HEAD
不是引用。
相对引用
过指定提交记录哈希值的方式在 Git 中移动不太方便。在实际应用时,并没有像本程序中这么漂亮的可视化提交树供你参考,所以你就不得不用 git log 来查查看提交记录的哈希值。
并且哈希值在真实的 Git 世界中也会更长(译者注:基于 SHA-1,共 40
位)。例如 fed2da64c0efc5293610bdd892f82a58e8cbc5d8。
比较令人欣慰的是,Git
对哈希的处理很智能。你只需要提供能够唯一标识提交记录的前几个字符即可。因此可以仅输入
fed2 而不是上面的一长串字符。
相对引用可以理解为查询节点的父节点或祖先节点,有两个简单用法:
- 使用
^向上移动 1 个提交记录,可以叠加,如HEAD^和HEAD^^ - 使用
~<num>向上移动多个提交记录,如~3 - 上述两种可以混合使用及链式使用,如
HEAD^^~2^
我使用相对引用最多的就是移动分支。可以直接使用 -f
选项让分支指向另一个提交。例如:
1 | git branch -f main HEAD~3 |
上面的命令会将 main 分支强制指向 HEAD 的第 3 级 parent 提交。
撤销变更
在 Git 里撤销变更的方法很多。和提交一样,撤销变更由底层部分(暂存区的独立文件或者片段)和上层部分(变更到底是通过哪种方式被撤销的)组成。
1 | 撤销方式 1 |
git reset
通过把分支记录回退几个提交记录来实现撤销改动。你可以将这想象成“改写历史”。git
reset 向上移动分支,原来指向的提交记录就跟从来没有提交过一样。
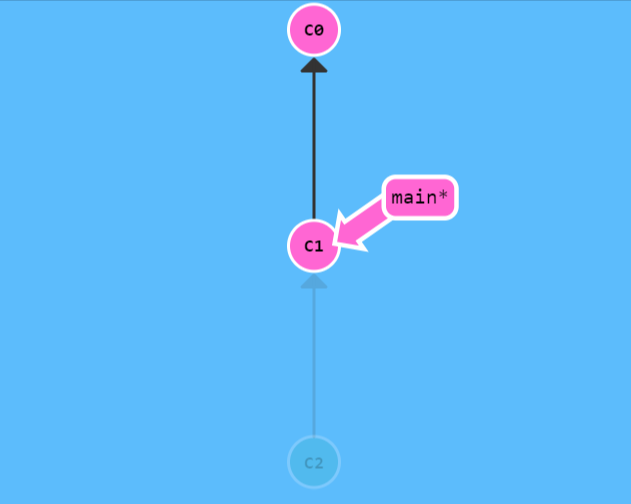
虽然在你的本地分支中使用 git reset
很方便,但是这种“改写历史”的方法对大家一起使用的远程分支是无效的哦!为了撤销更改并分享给别人,我们需要使用
git revert。
整理提交记录
1 | 将一些提交记录复制到 HEAD 下 |
选择 parent 提交记录: 操作符 ^ 与 ~
符一样,后面也可以跟一个数字。
但是该操作符后面的数字与 ~
后面的不同,并不是用来指定向上返回几代,而是指定合并提交记录的某个
parent 提交。还记得前面提到过的一个合并提交有两个 parent
提交吧,所以遇到这样的节点时该选择哪条路径就不是很清晰了。
Git 默认选择合并提交的“第一个” parent 提交,在操作符 ^
后跟一个数字可以改变这一默认行为。(感觉这个有点不是很好区分第几个,可能用哈希值的方式会好些)
标签
1 | 在 c1 提交记录上创建一个名为 v1 的标签 |
Git 的 tag 就是干这个用的啊,它们可以(在某种程度上 —— 因为标签可以被删除后重新在另外一个位置创建同名的标签)永久地将某个特定的提交命名为里程碑,然后就可以像分支一样引用了。
更难得的是,它们并不会随着新的提交而移动。你也不能切换到某个标签上面进行修改提交,它就像是提交树上的一个锚点,标识了某个特定的位置。
由于标签在代码库中起着“锚点”的作用,Git
还为此专门设计了一个命令用来描述离你最近的锚点(也就是标签),它就是
git describe!
Git Describe 能帮你在提交历史中移动了多次以后找到方向;当你用
git bisect(一个查找产生 Bug
的提交记录的指令)找到某个提交记录时,或者是当你坐在你那刚刚度假回来的同事的电脑前时,
可能会用到这个命令。
1 | git describe <ref> |
<ref> 可以是任何能被 Git
识别成提交记录的引用,如果你没有指定的话,Git
会使用你目前所在的位置(HEAD)
输出结果:<tag>_<numCommits>_g<hash>
tag 表示的是离 ref 最近的标签,
numCommits 是表示这个 ref 与 tag
相差有多少个提交记录, hash 表示的是你所给定的
ref 所表示的提交记录哈希值的前几位。当 ref
提交记录上有某个标签时,则只输出标签名称。
远程仓库
首先,远程仓库就是一个托管在服务器上的本地仓库的拷贝。
1 | 拷贝远程仓库到本地 |
拷贝后,本地仓库多了一个名为 origin/main 的分支,
这种类型的分支就叫远程分支。由于远程分支的特性导致其拥有一些特殊属性。
远程分支反映了远程仓库(在你上次和它通信时)的状态。这会有助于你理解本地的工作与公共工作的差别 —— 这是你与别人分享工作成果前至关重要的一步.
远程分支有一个特别的属性,在你切换到远程分支时,自动进入分离 HEAD 状态。Git 这么做是出于不能直接在这些分支上进行操作的原因, 你必须在别的地方完成你的工作, (更新了远程分支之后)再用远程分享你的工作成果。
Git 远程仓库相当的操作实际可以归纳为两点:向远程仓库传输数据以及从远程仓库获取数据。既然我们能与远程仓库同步,那么就可以分享任何能被 Git 管理的更新(因此可以分享代码、文件、想法、情书等等)。
1 | 拉取远程更新(但不更新本地分支) |
git fetch 完成了仅有的但是很重要的两步:
- 从远程仓库下载本地仓库中缺失的提交记录
- 更新远程分支指针(如 origin/main)
git fetch
实际上将本地仓库中的远程分支更新成了远程仓库相应分支最新的状态,但并不会改变你本地仓库的状态。它不会更新你的
main 分支,也不会修改你磁盘上的文件。所以, 你可以将
git fetch 的理解为单纯的下载操作。
在开发社区里,有许多关于 merge 与 rebase 的讨论。以下是关于 rebase 的优缺点:
- 优点:Rebase 使你的提交树变得很干净, 所有的提交都在一条线上
- 缺点:Rebase 修改了提交树的历史
比如, 提交 C1 可以被 rebase 到 C3 之后。这看起来 C1 中的工作是在 C3 之后进行的,但实际上是在 C3 之前。 一些开发人员喜欢保留提交历史,因此更偏爱 merge。而其他人(比如我自己)可能更喜欢干净的提交树,于是偏爱 rebase。仁者见仁,智者见智。
小技巧
一些日常学习与工作中用到的 git 小技巧
屏蔽追踪
要求:本地仓库与远程仓库中都有一个 config 文件,现在希望本地仓库中对 config 的修改不被同步到远程仓库,且保持远程仓库的 config 文件不变。
1 | 1. 标记 config 文件为 |