Information
- Title: Modality-Agnostic Debiasing for Single Domain Generalization
- Author: Sanqing Qu, Yingwei Pan, Guang Chen, Ting Yao, Changjun Jiang, Tao Mei
- Institution: 同济大学
- Year: 2023
- Journal: CVPR
- Source: Arxiv, PDF
- Cite: Sanqing Qu, Yingwei Pan, Guang Chen, Ting Yao, Changjun Jiang, Tao Mei, IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR), 2023
- Idea: 针对分类器设置了两个分支分布提取域特定特征以及域不变特征,该方法可以在各种模态下即插即用
1 | @article{Qu2023ModalityAgnosticDF, |
Abstract
现有的域泛化方法大多是基于特定模态的,作者提出了一种通用的模态不可知无偏(Modality-Agnostic Debiasing, MAD)框架用于单源域泛化。MAD 引入了两个分支分类器:一个偏置分支提取域特定(表面)特征,一个泛化分支基于偏置分支捕获域泛化特征。MAD 对大多单源域方法都能即插即用,并在实验中验证了有效性。
Introduction
有研究表面图像具有域特定特征的两个主要原因是纹理和风格,所以很多方法都致力于生成多样化的纹理和风格来使模型学习更广泛的特征,但这些方法通常是基于特点模态的,若是针对其他模态,例如三维点云,就无法迁移过去了,三维点云的域偏移被认为是三维结构信息的差异。
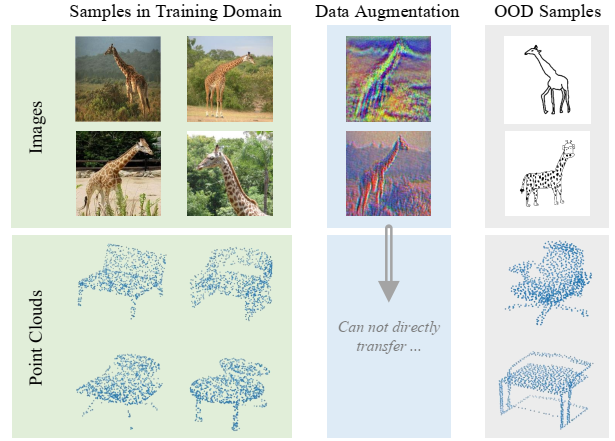
针对这一点,作者提出直接加强分类器识别域特定特征的能力,同时强化域泛化特征的学习,这种思路完全消除了特定模态数据增强的需求,因此是一种单源域泛化通用的模态不可知算法。具体的实现方法是作者设计的 MAD 框架,MAD将提取特征的backbone与双分支分类器进行集成,两个分支分别是:偏置分支使用多头协同分类器提取表面和域特定特征,泛化分支从偏置分支获取的知识来学习获取与泛化特征。
作者在 1D 文本,2D 图像,3D 点云的任务上进行了实验,表明了 MAD 方法的有效性。
Method
单源域泛化是在单个源域 𝒟S 上进行训练能泛化到未见过的目标域 {𝒟T1, 𝒟T2, ⋯, 𝒟TZ} . 考虑 K 分类任务:𝒟S = {(xi, yi)}i = 1n ,DNN网络结构用 F = g ∘ f, 其中 g 是分类器,f 是特征提取器。对于域泛化有这样的一般性假设:域 𝒟S 的域泛化特征 eg 在各个域上是一致的,域特定特征 es 是不同域上是不同的。在这种假设下,基于域泛化特征的分类器是比基于域特定特征的分类器是要更好的。在这种假设下,直接在 𝒟S 上应用经验风险最小化(ERM) 会导致次优的模型,无法泛化到未见过的域。因为特征提取器通常会倾向于提取更简单的特征也就是域特定特征而更加忽视域泛化的特征导致泛化性能的下降。
作者认为使用数据增广来提高特征提取器提取域泛化特征的能力这种做法局限性太大,大多只能适用于图像模态,所以提出直接加强分类器识别域特定特征的能力,同时强调学习域泛化特征,以此缓解对数据增广的需要,作为一种通用的与模态无关的域泛化方法。
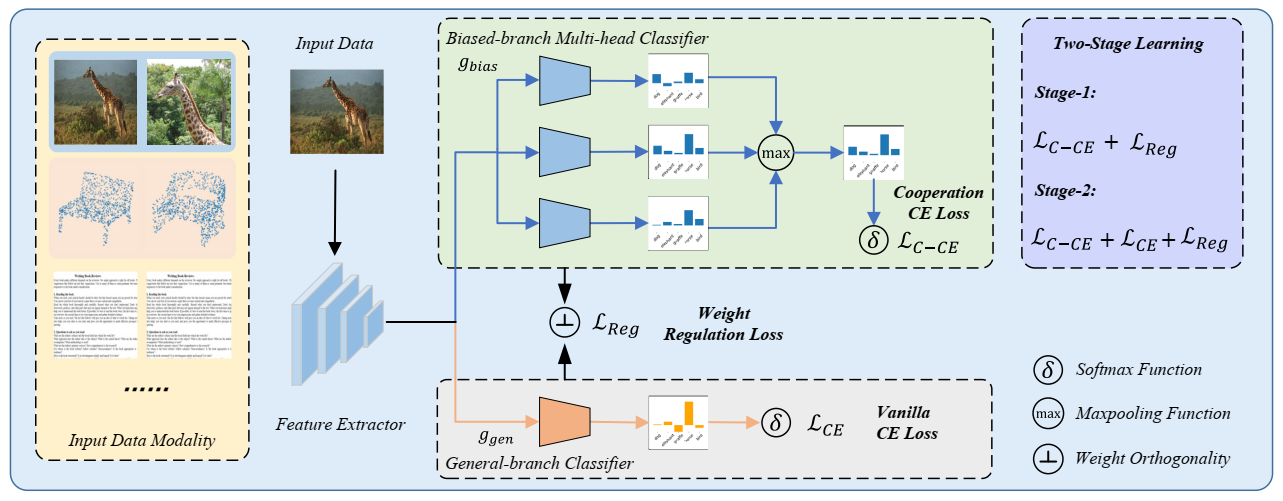
具体的实现方法是作者设计的 MAD 框架,MAD将提取特征的backbone与双分支分类器进行集成,两个分支分别是:偏置分支使用多头协同分类器提取表面和域特定特征,泛化分支从偏置分支获取的知识来学习获取与泛化特征。
作者认为,单一的简单分类器没法学习到所有域特定特征,例如对于图像,背景、纹理、高频模式都是属于域特定的特征,所以作者设计了一个多头协同的分类器 gbias : ℝD → ℝK × M 来学习更多的特征,使用协同交叉熵损失来学习这个分支: $$ \mathcal{L}_{C-C E}=\mathbb{E}_{x, y} \sum_{k=1}^{K}-\mathbb{1}_{[k=y]} \log \frac{\exp \left(\max \left(v_{k}(x)\right)\right)}{\sum_{j=1}^{K} \exp \left(\max \left(v_{j}(x)\right)\right)}, $$ vk(x) 表示 x 样本的第 k 个类的分类器结果,M 表示分类头的数量。该模块并不要求所有分支的分类器都能准确预测分类结果,而是只需要一个分类器能准确预测就可以了,该模块更强调协同进行分类,另外,由于 max 函数不可微,所以在实现中作者使用 log-sum-exp 来近似。
一般情况下 M 的值在 [1, D//K − 1] 是比较合适的,作者使用了交叉验证来选择合适的 M 的值。
接下来要考虑如何抑制域相关的特征来学习到域无关的特征,对于这一点,作者提出了泛化分支分类器ggen : ℝD → ℝK 来捕获域无关的特征。
用 Wbias ∈ ℝK × M × D 和 Wgen ∈ ℝK × D 分布表示两个模块中分类器的权重,作者提出一种直观的方案是使 Wbias 和 Wgen 正交: $$ \mathcal{L}_{C E}=\mathbb{E}_{x, y} \sum_{k=1}^{K}-\mathbb{1}_{[k=y]} \log \frac{\exp \left(u_{k}(x)\right)}{\sum_{j=1}^{K} \exp \left(u_{j}(x)\right)} $$
$$ \mathcal{L}_{\text {Reg }}=\frac{1}{K} \sum_{k=1}^{K}\left\|W_{\text {bias }}[k,:] W_{\text {gen }}[k,:]^{T}\right\|_{F}^{2} $$
其中 uk(x) 表示 x 样本的第 k 个类的分类器结果。但如果一开始就优化整个网络可能无法保证分类器 ggen 关注到域无关的特征,为了解决这个问题,作者设计了一种两阶段的学习机制来实现两个分支之间的交互。在第一阶段,只使用 ℒC − CE 和 ℒReg 来优化网络,鼓励偏置分支学习领域相关的特征,在第二阶段,再使用三个损失函数同时优化整个网络: minf, gbias, ggenℒC − CE + ℒReg + 𝟙[pro ≥ T]ℒCE 这里 pro 表示训练进度,达到一定进度才会加上最后一段损失函数。而 T 的大小取决于训练集的大小和训练难度。作者的实验中,对识别任务设置为 T = 3(共 50 epoch), 对于语义分割设置 T = 6% 的 epoch。

正在测试阶段只使用泛化分支的分类器,所以 MAD 不会增加计算成本。
Experiment
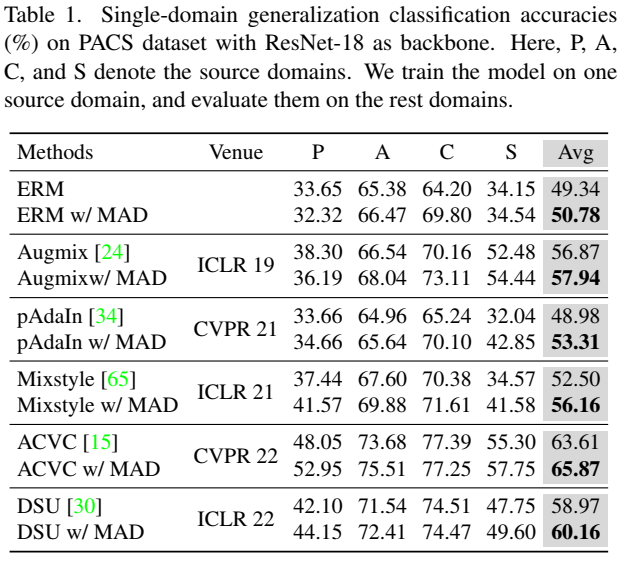
首先是图像泛化数据集 PACS 的测试
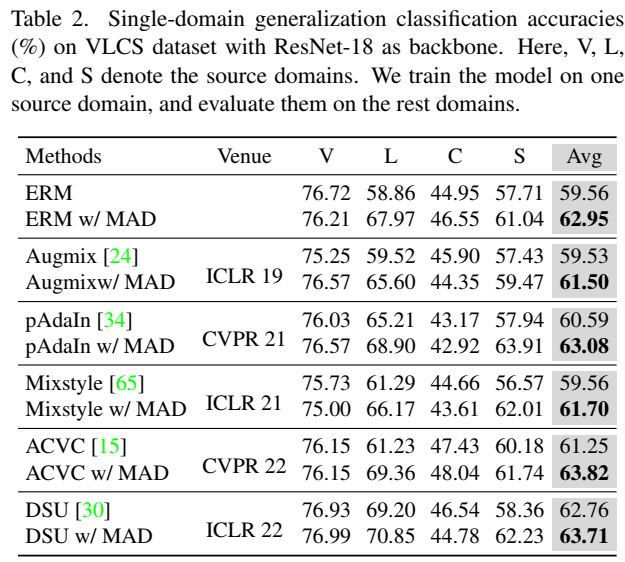
同样类型的 VLCS 数据集
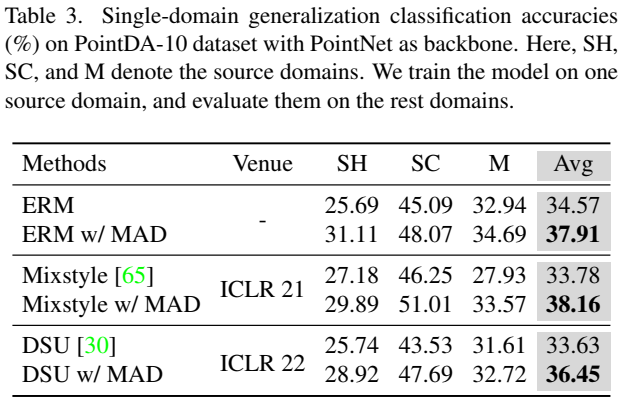
三维点云在 PointDA-10 数据集的域泛化实验
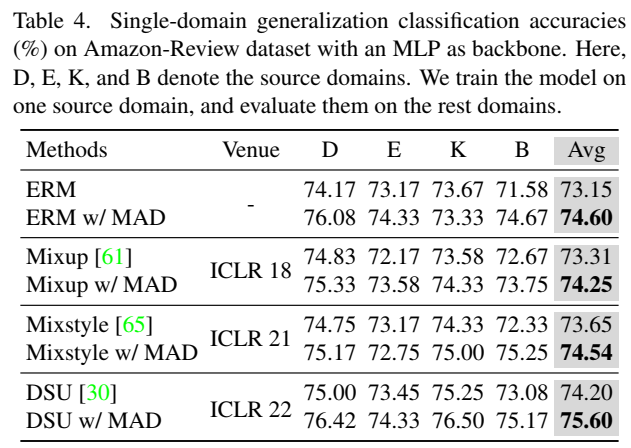
文本分类任务的测试使用的是 Amazon-Review 数据集:
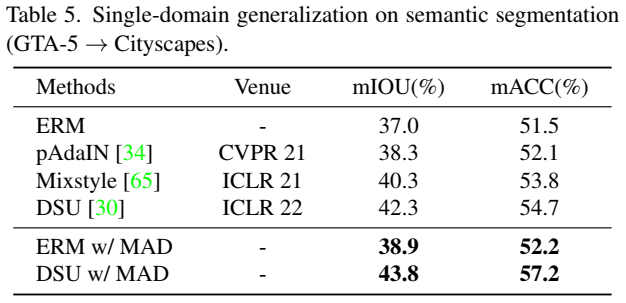
语义分割
消融实验:

表明两阶段训练和多头分类器都是有效的
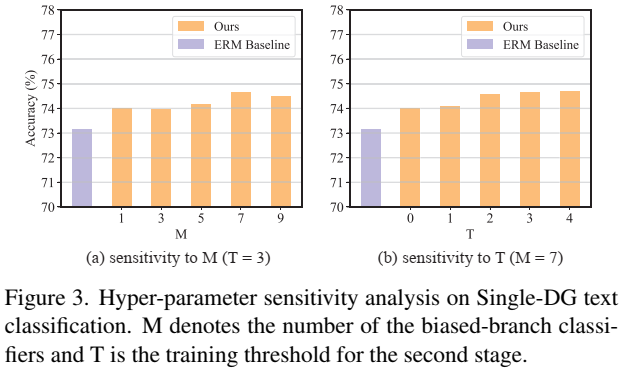
多头分类器头的数量(M) 和两阶段训练的转折时间点(T)
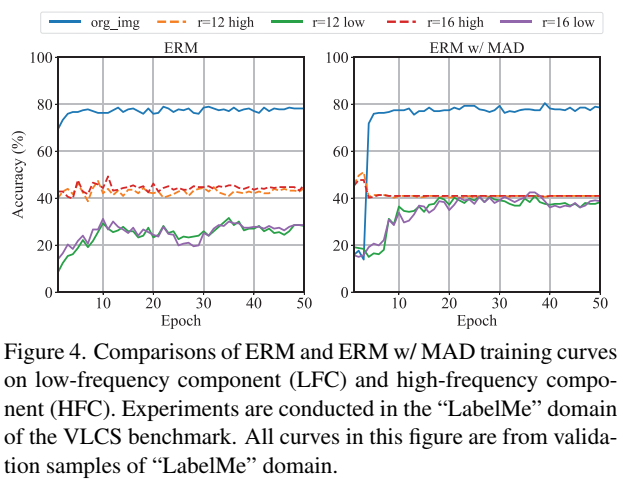
MAD对于低频成分能更有效提高,也证明了低频成分是更域泛化的特征。
最后是两个可视化结果
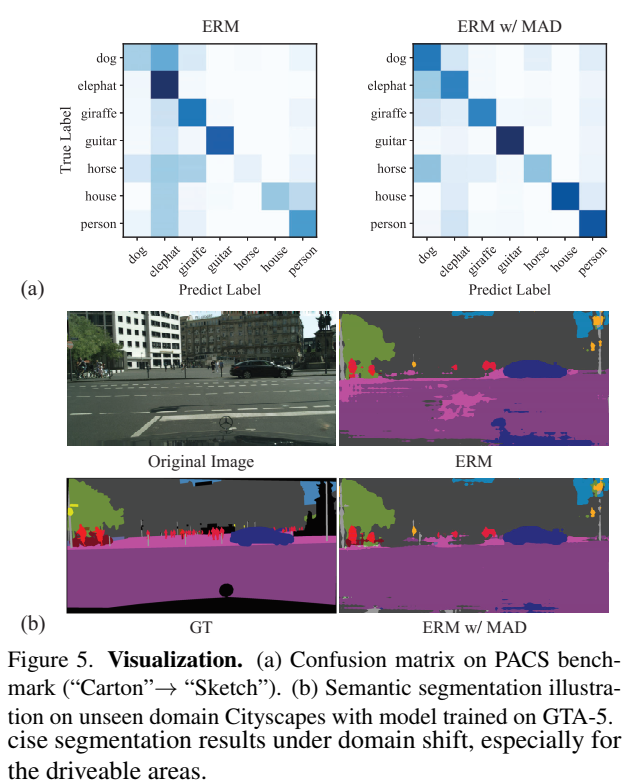
一些附录的展示:
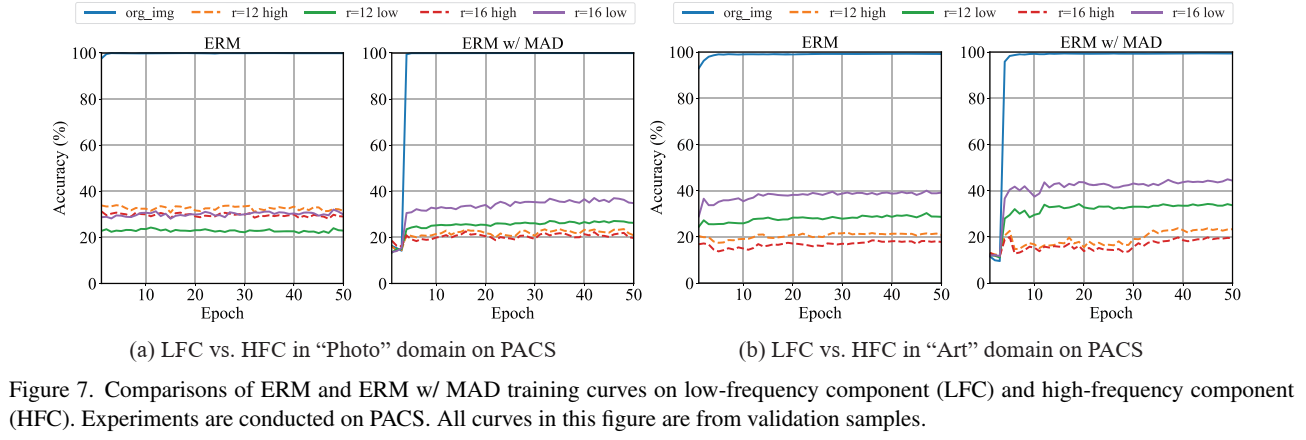
这幅图还是在说明前面的那个观点:低频特征泛化,高频特征是域特定特征,MAD中分类器更关注域泛化特征即低频特征。
Conclusion
这篇论文指出现有的域泛化方法大多是针对特定模态的,作者提出了一种模态通用的域泛化方法,在分类器方面一方面加强了对域特定特征的学习,另一方面利用已经学到的域特定特征来指导学习域泛化特征,这种方法可以和现有的方法结合并在多种模态任务中取得了良好的效果。
如有错漏,欢迎指正!如果对你有帮助的话,请给我点个赞吧~
欢迎前往 我的博客 查看更多笔记