Cite: Ilke Cugu, Massimiliano Mancini, Yanbei Chen,
Zeynep Akata; Proceedings of the IEEE/CVF Conference on Computer Vision
and Pattern Recognition (CVPR) Workshops, 2022, pp. 4165-4174
Idea: 原图与腐蚀图像的 CAM
图应该一致,即注意力集中在相同区域
1 2 3 4 5 6 7 8
@InProceedings{Cugu_2022_CVPR, author = {Cugu, Ilke and Mancini, Massimiliano and Chen, Yanbei and Akata, Zeynep}, title = {Attention Consistency on Visual Corruptions for Single-Source Domain Generalization}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops}, month = {June}, year = {2022}, pages = {4165-4174} }
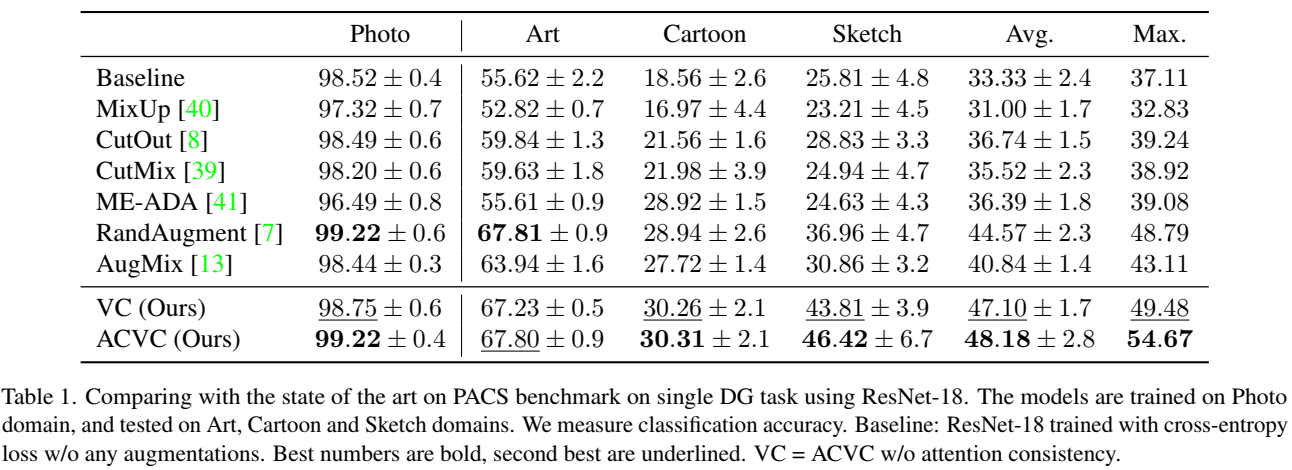
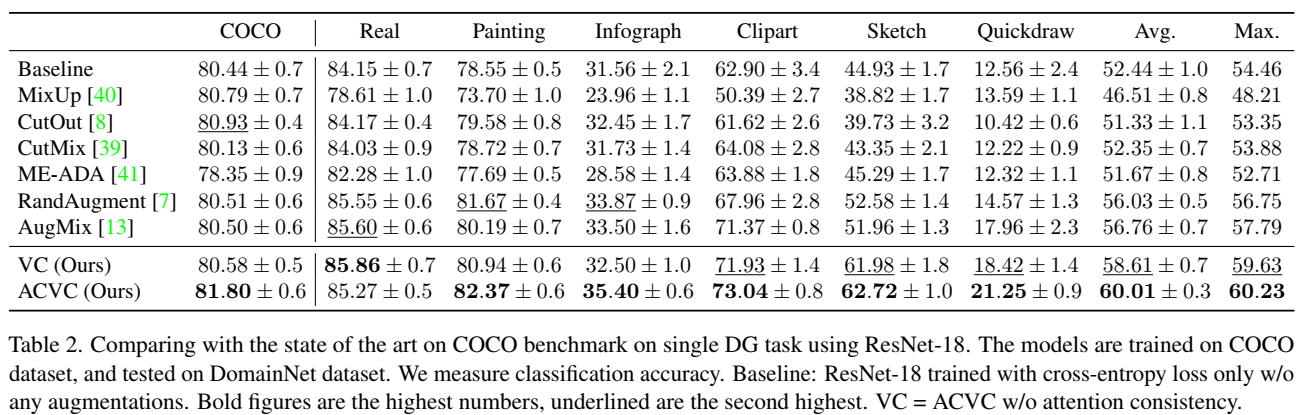
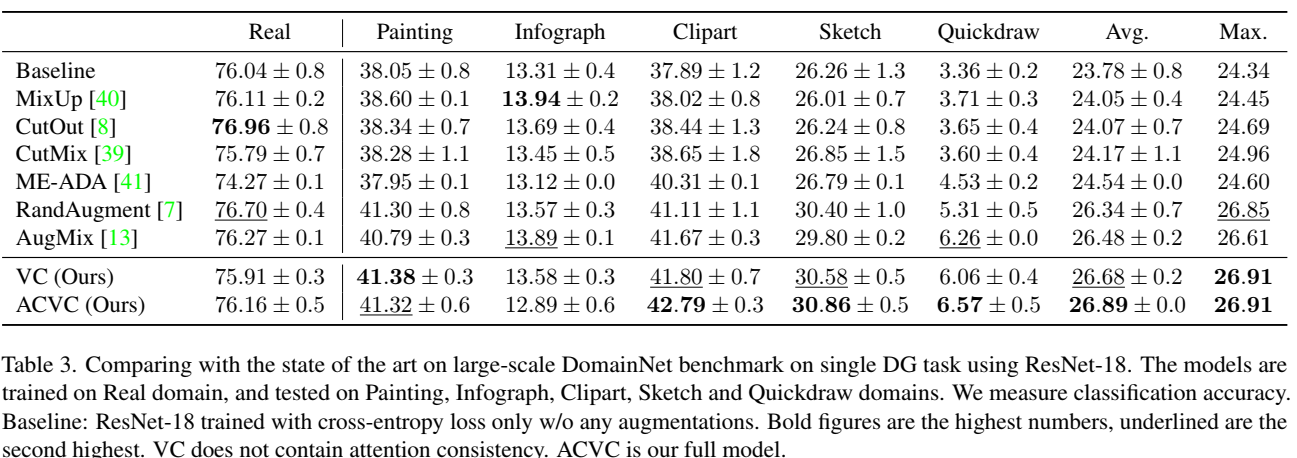
Abstract
通过改变训练图像来模拟新的域,并对同一样本的不同视图添加一致性注意力。作者将该方法命名为视觉腐蚀的注意力一致性(Attention
Consistency on Visual Corruptions, ACVC)
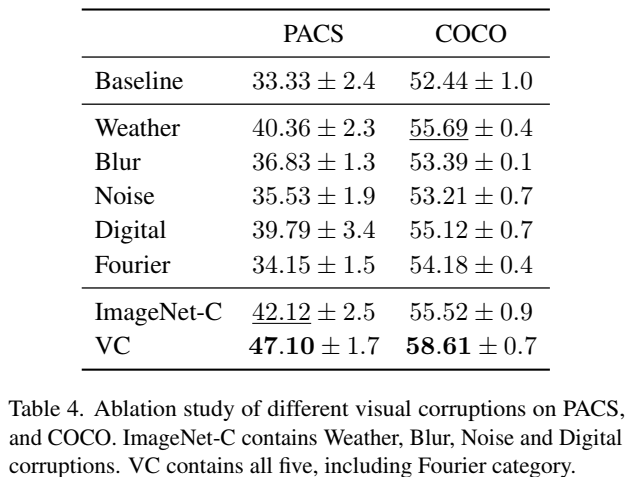
# 0-18 ImageNet-C 的 19 中数据增强 if corruption_name in get_corruption_names('all'): x = corrupt(x, corruption_name=corruption_name, severity=severity) x = PILImage.fromarray(x)
# 基于傅里叶变换的 3 中数据增强 elif corruption_name in custom_corruptions: x = custom_corruptions[corruption_name](x, severity=severity)
else: assertTrue, "%s is not a supported corruption!" % corruption_name
# For each channel, pass filter fft_img_filtered = [] for ichannel inrange(fft_img.shape[2]): fft_img_channel = fft_img[:, :, ichannel] temp = self.filter_circle(TFcircle, fft_img_channel) fft_img_filtered.append(temp) fft_img_filtered = np.array(fft_img_filtered) fft_img_filtered = np.transpose(fft_img_filtered, (1, 2, 0)) x = np.clip(np.abs(self.inv_FFT_all_channel(fft_img_filtered)), a_min=0, a_max=1)
x = PILImage.fromarray((x * 255.).astype("uint8")) return x
defconstant_amplitude(self, x, severity): """ A visual corruption based on amplitude information of a Fourier-transformed image Adopted from: https://github.com/MediaBrain-SJTU/FACT """ x = x.astype("float32") / 255. c = [.05, .1, .15, .2, .25][severity - 1]
x = PILImage.fromarray((x * 255.).astype("uint8")) return x
defphase_scaling(self, x, severity): """ A visual corruption based on phase information of a Fourier-transformed image Adopted from: https://github.com/MediaBrain-SJTU/FACT """ x = x.astype("float32") / 255. c = [.1, .2, .3, .4, .5][severity - 1]
defCAM_neg(self, c): result = c.reshape(c.size(0), c.size(1), -1) result = -nn.functional.log_softmax(result / self.T, dim=2) / result.size(2) result = result.sum(2)
return result
defCAM_pos(self, c): result = c.reshape(c.size(0), c.size(1), -1) result = nn.functional.softmax(result / self.T, dim=2)
return result
defforward(self, c, ci_list, y, segmentation_masks=None): """ CAM (batch_size, num_classes, feature_map.shpae[0], feature_map.shpae[1]) based loss Argumens: :param c: (Torch.tensor) clean image's CAM :param ci_list: (Torch.tensor) list of augmented image's CAMs :param y: (Torch.tensor) ground truth labels :param segmentation_masks: (numpy.array) :return: """ c1 = c.clone() c1 = Variable(c1) c0 = self.CAM_neg(c)
# Top-k negative classes c1 = c1.sum(2).sum(2) index = torch.zeros(c1.size()) c1[range(c0.size(0)), y] = - float("Inf") topk_ind = torch.topk(c1, 3, dim=1)[1] index[torch.tensor(range(c1.size(0))).unsqueeze(1), topk_ind] = 1 index = index > 0.5
# Negative CAM loss neg_loss = c0[index].sum() / c0.size(0) for ci in ci_list: ci = self.CAM_neg(ci) neg_loss += ci[index].sum() / ci.size(0) neg_loss /= len(ci_list) + 1
# Positive CAM loss index = torch.zeros(c1.size()) true_ind = [[i] for i in y] index[torch.tensor(range(c1.size(0))).unsqueeze(1), true_ind] = 1 index = index > 0.5 p0 = self.CAM_pos(c)[index] pi_list = [self.CAM_pos(ci)[index] for ci in ci_list]
# Middle ground for Jensen-Shannon divergence p_count = 1 + len(pi_list) if segmentation_masks isNone: p_mixture = p0.detach().clone() for pi in pi_list: p_mixture += pi p_mixture = torch.clamp(p_mixture / p_count, 1e-7, 1).log()