Information
- Title: Lipschitz Normalization for Self-Attention Layers with Application to Graph Neural Networks
- Author: George Dasoulas, Kevin Scaman, Aladin Virmaux
- Institution: Noah’s Ark Lab, Huawei Technologies France
- Year: 2021
- Journal: ICML
- Source: Arxiv, Github repository
- Idea: 提出了 LipschitzNorm 来提高 GNN 模型性能,并利用 Lipschitz 连续性在理论上证明了方法的有效性
1 | @inproceedings{inproceedings, |
该论文仅做略读
Abstract
通过对注意力分数进行 normalization 使深度注意力模型具有 Lipschitz 连续性能显著提高模型性能。
梯度爆炸现象使 GAT(图注意力网络)在基于梯度下降的训练算法中性能降低,为解决这一问题,作者引入 LipschitzNorm 方法来使得模型具有 Lipschitz 连续性。
Introduction
主要用于基于注意力的图神经网络,包括 GAT (graph attention networks) 和 GT (graph transformers)
除此之外,作者还展示了没有 norm 原始的注意力机制在这种结构中因为缺乏 Lipschitz 连续性会导致梯度爆炸。
Method
对 g(x) = WTX 的正则化方法流程

对 Transformer 的 LipschitzNorm 包含三步:
- 计算查询 Q 的 F-范数 $u = \sqrt{\sum_i \|q_i\|_2^2}$.
- 计算输入向量的最大2-范数 v = maxi∥xi∥2 (或 Transformer的 v = maxi∥ki∥2 和 w = maxi∥vi∥2)
- 最后用 分数函数除以 uv (或 Transformer 的 max {uv, uw, vw})
Detail
第 3 节给了一些定义,包括各种范数、Lipschitz 连续、注意力模型等
第 4 节说明了一个问题:注意力倾向于注意少数值,对少数值加权后会使得大的数更大导致梯度也更大。作者给出了注意力模型梯度范数的上界
第 5 节详细说明了作者提出的方法 LipschitzNorm
第 6 节指出模型 Lipschitz 常数的上界是每层 Lipschitz 常数的累积,所以经过一层层的累积导致了梯度爆炸
下图中左图展示了梯度爆炸的现象,右图展示了添加 Norm 后可以缓解梯度爆炸

下图说明梯度爆炸也会导致性能降低
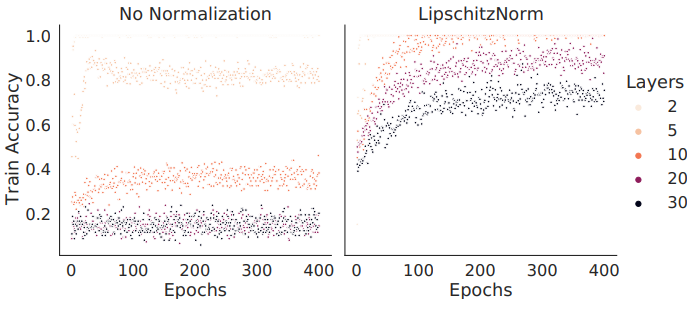
Experiment
都是图网络的,就不看了
Conclusion
提出了 LipschitzNorm 的正则化方法,用于使自注意力层保持 Lipschitz 连续性,效果很好…
Others
代码实现
实话说这个 scatter 操作有点懵,没太懂是干什么的
1 | import torch, torch.nn as nn |
scatter 函数功能如下

References
如果对你有帮助的话,请给我点个赞吧~
欢迎前往 我的博客 查看更多笔记