Information
- Title: Domain Generalization through Audio-Visual Relative Norm Alignment in First Person Action Recognition
- Author: Mirco Planamente, Chiara Plizzari, Emanuele Alberti, Barbara Caputo
- Institution: Politecnico di Torino, Istituto Italiano di Tecnologia, CINI Consortium
- Year: 2022
- Journal: WACV
- Source: Arxiv, Open Access
- Cite: Mirco Planamente, Chiara Plizzari, Emanuele Alberti, Barbara Caputo; Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2022, pp. 1807-1818
- Idea: 提出通过范数对齐的方法来进行不同模态间的重平衡
1 | @InProceedings{Planamente_2022_WACV, |
Abstract
在这项工作中,作者介绍了一种新的用于以人为中心的动态识别的域泛化方法,提出了一种新的视觉语音损失,称为相对范数对齐(Relative Norm Alignment)损失。它通过调整两种模态的特征范数表征,在不同域的训练过程中重新平衡两种模态的贡献。
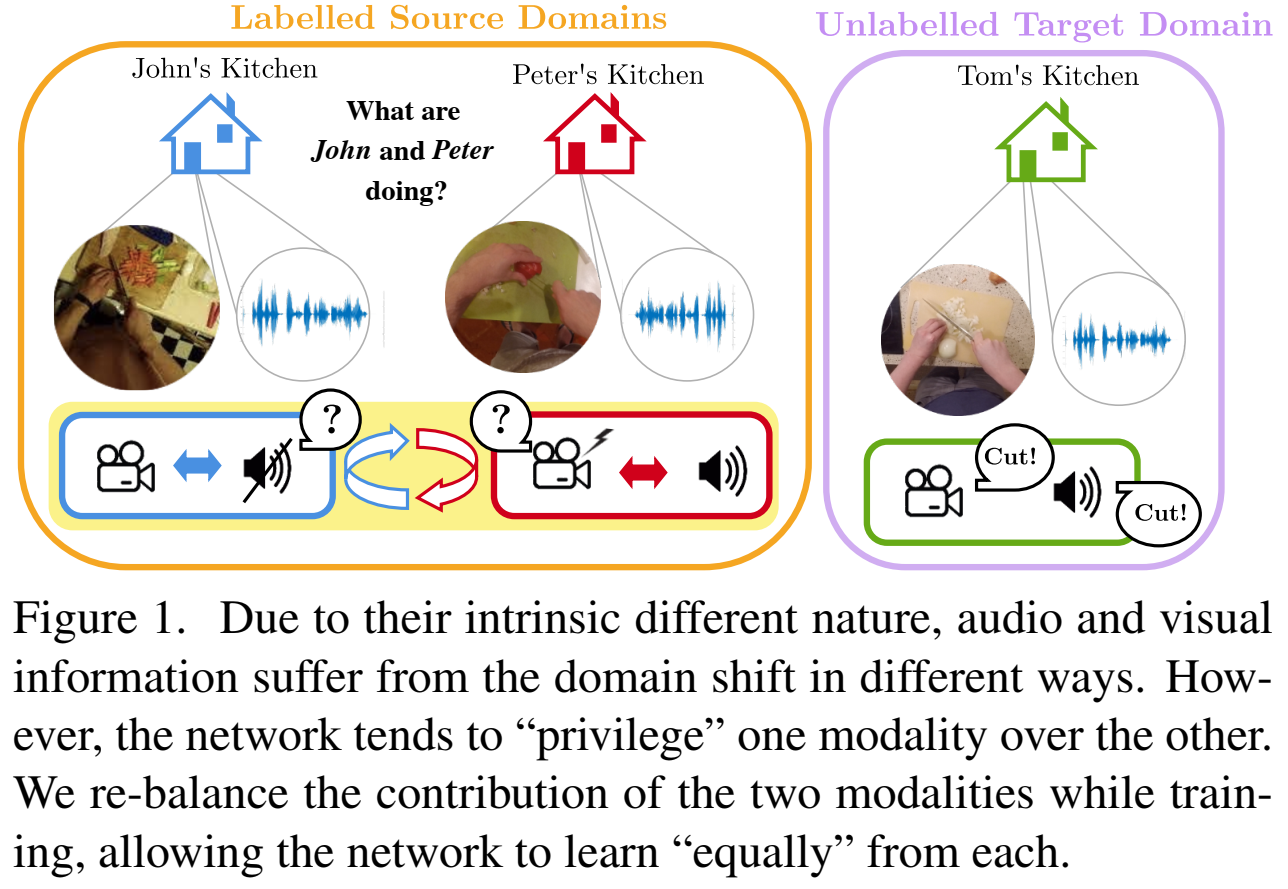
Introduction
图像和语音结一个是有助于域泛化的,但在实际应用中却没有达到预想的效果,可能的原因是卷积神经网络提取特征的能力受限,这种问题的根本原因是在训练过程中不同模式的不平衡导致的,据此作者提出通过范数对齐的方法来重新平衡不同模态之间的平均特征范数。
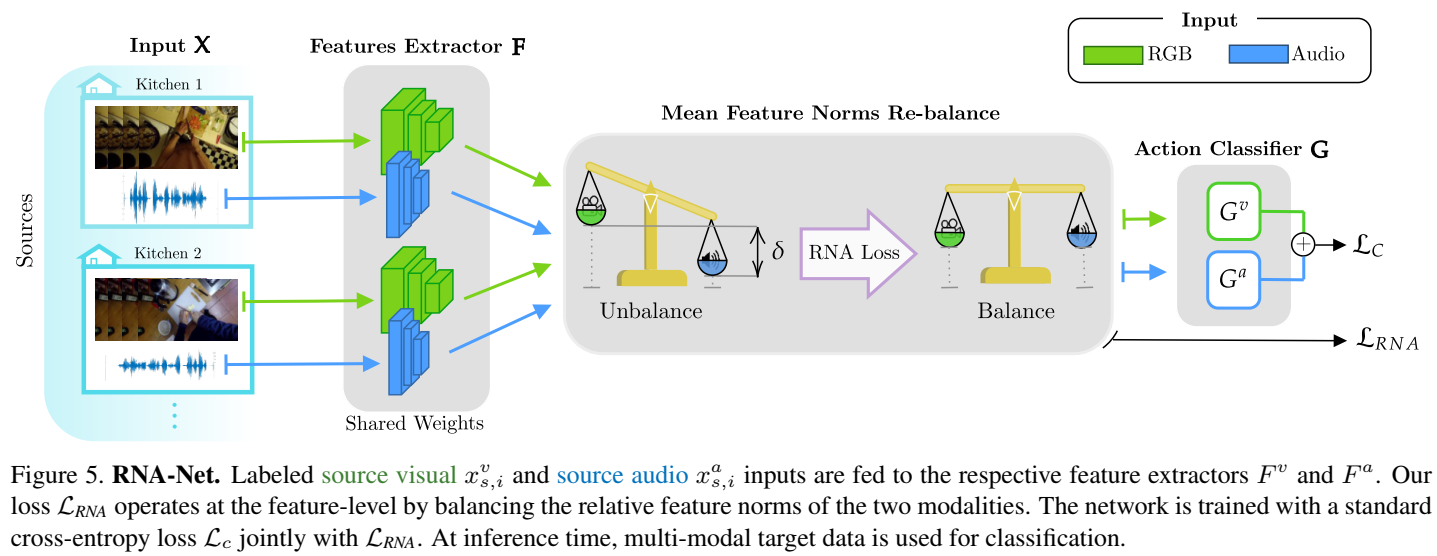
Method
在这些结果的激励下,我们提出了一个简单但有效的损失,其目标是在跨多个源域训练期间重新平衡平均特征范数,以便网络能够充分利用联合训练,特别是在跨域场景中。事实上,当重新平衡规范时,两种模式的性能都有所提高。注意,更小的范数信息量更少的概念是用来证明网络对音频模式的偏好只是因为它的范数更高(高于RGB),但这并不意味着RGB对任务的信息量更少;事实上,重新平衡后的规范范围更接近原始RGB规范。
总的损失分成两个部分: ℒ = ℒC + λℒRNA
即分类损失和作者提出的相对范数对齐损失,后者具体而言是: $$
\mathcal{L}_{R N
A}=\left(\frac{\mathbb{E}\left[h\left(X^{v}\right)\right]}{\mathbb{E}\left[h\left(X^{a}\right)\right]}-1\right)^{2}
$$ 作者同样提出了一种硬约束 Hard Norm Alignment (HNA): ℒHNA = ∑m(𝔼[h(Xm)] − k)2
Experiment
- 数据集:EPIC-Kitchens-55
Conclusion
在本文中,我们首次表明,通过利用音频和视觉模式的互补性可以有效地实现第一人称动作识别中不可见域泛化,从而揭示了“范数不平衡”问题。我们对多模态研究提出了创新的观点,提出了模态特征范数作为度量单位。为此,我们设计了一种新的跨模态损失,直接作用于两种模态的相对特征范数。我们认为这种基于范数的方法是一种很有前途的多模态学习新方法,可能会引起许多其他研究领域的兴趣。
References
如果对你有帮助的话,请给我点个赞吧~
欢迎前往 我的博客 查看更多笔记