Information
- Title: Orthogonal Transformer: An Efficient Vision Transformer Backbone with Token Orthogonalization
- Author: 黄怀波, 周晓强 , 赫然
- Institution: 中国科学院自动化研究所,中国科学院大学,中国科学技术大学
- Year: 2022
- Journal: NeurIPS
- Source: PDF, Offical Code (截至本文完成还是空的), openreview
- Cite: Huang H, Zhou X, He R. Orthogonal Transformer: An Efficient Vision Transformer Backbone with Token Orthogonalization[C]//Advances in Neural Information Processing Systems.
- Idea: 提出了正交 transformer,设计得很巧妙
1 | @inproceedings{huang2022Orthogonal, |
Abstract
这篇文章提出了一种通用视觉Transformer骨干网络称为正交 Transformer,针对局部自注意力和全局自注意力进行建模,提出了一种正交自注意力机制(orthogonal self-attention, OSA),即在一个正交子空间中进行注意力的计算,并且该空间可以逆映射回空域.
在本文中,我们提出了一种正交自注意力机制,通过将视觉令牌特征变换到低分辨率的正交空间再进行自注意力计算,每一个正交令牌都可以感知到所有的视觉令牌,从而有效建模局部特征相关性和全局特征依赖关系。我们提出了一种内生的正交变换矩阵来保证令牌特征的正交性,该正交变换矩阵可以直接作为网络参数优化更新而无需引入额外的正交约束监督。此外,我们还提出了一种基于位置编码的多层感知机并搭建了一个层次化的主干网络,称为正交Transformer网络。正交Transformer在图像分类、物体检测、实例分割和语义分割领域均取得了超越SOTA方法的性能,其中在ImageNet图像分类数据集上,在不引入额外训练数据的情况下,正交Transformer达到了85.4%的分类精度。
Introduction
视觉Transformer中的自注意力机制,可以有效建模图像中的全局依赖关系,但对于检测、分割等密集预测任务,往往面临计算开销大的问题。目前对自注意力机制的改进工作,如降采样自注意力计算、局部自注意力计算、以及空洞自注意力计算等,虽然可以通过降低令牌数量来减少计算量,建模全局信息,但是缺乏对局部特征的处理,难以同时兼顾局部特征相关性和全局依赖建模。

这篇文章提出的正交注意力能补充全局依赖并且也不会损失低层次的细节信息。
Method
【内生正交变换】
在本文中,我们首先提出将特征投影到正交空间再进行自注意力计算。这样做包含以下四点优势:1)正交空间的特征分辨率更低,计算复杂度也就更小。2)正交变换矩阵的逆矩阵即为转置矩阵,可以在不丢失信息的情况下,便捷地实现原始特征空间和正交特征空间的可逆变换。3)正交变换可以将令牌特征变换为若干组线性无关的特征组,有助于自注意力机制发掘特征表示中的不同属性。4)正交变换显式建模了相邻特征依赖和局部特征相关性。
我们基于以下定理,来利用Householder变换 (H = I − 2uuT )来构建内生正交变换矩阵。
定理1:任意实值n × n正交矩阵,可以表示为至多 n 个实值Householder变换矩阵的乘积。定理证明过程请见论文附录。
因此,对于n个令牌特征,内生正交变换矩阵可以表示为: $$ \mathbf{A}=\mathbf{H}_{0} \mathbf{H}_{1} \cdots \mathbf{H}_{n-1}=\left(\mathbf{I}-2 \frac{\mathbf{v}_{0} \mathbf{v}_{0}^{\top}}{\left\|\mathbf{v}_{0}\right\|^{2}}\right)\left(\mathbf{I}-2 \frac{\mathbf{v}_{1} \mathbf{v}_{1}^{\top}}{\left\|\mathbf{v}_{1}\right\|^{2}}\right) \cdots\left(\mathbf{I}-2 \frac{\mathbf{v}_{n-1} \mathbf{v}_{n-1}^{\top}}{\left\|\mathbf{v}_{n-1}\right\|^{2}}\right) . $$ 其中vi为可学习的n维向量。这种构建正交变换矩阵的方式具有以下有点:1)表达能力强。根据定理1,矩阵A 可以被优化表示为任意的正交变换矩阵。2)便于优化。因为是内生式的构建方式,不需要隐入额外的正交监督约束,就可以保证该变换矩阵的正交性。
【正交自注意力机制】
如图1所示,基于上述提出的正交变换构建过程,我们提出了正交自注意力机制。具体计算过程如下:1)首先利用正交变换,将输入的令牌特征由原始视觉空间变换到正交空间。2)在正交空间里,首先将特征重排为线性独立的若干组特征,然后利用自注意力机制,分组计算全局特征依赖关系。3)利用正交变换矩阵的转置矩阵,将正交特征投影回原始视觉空间,进行下一步的计算。值得注意的是,正交自注意力计算模块在可以有效同时建模全局信息和局部细节的同时,能够将全局自注意力机制的计算复杂度由 O((hw)2) 减少为O((hw)2/m2),其中 m表示正交变换的窗口大小。
【正交Transformer】
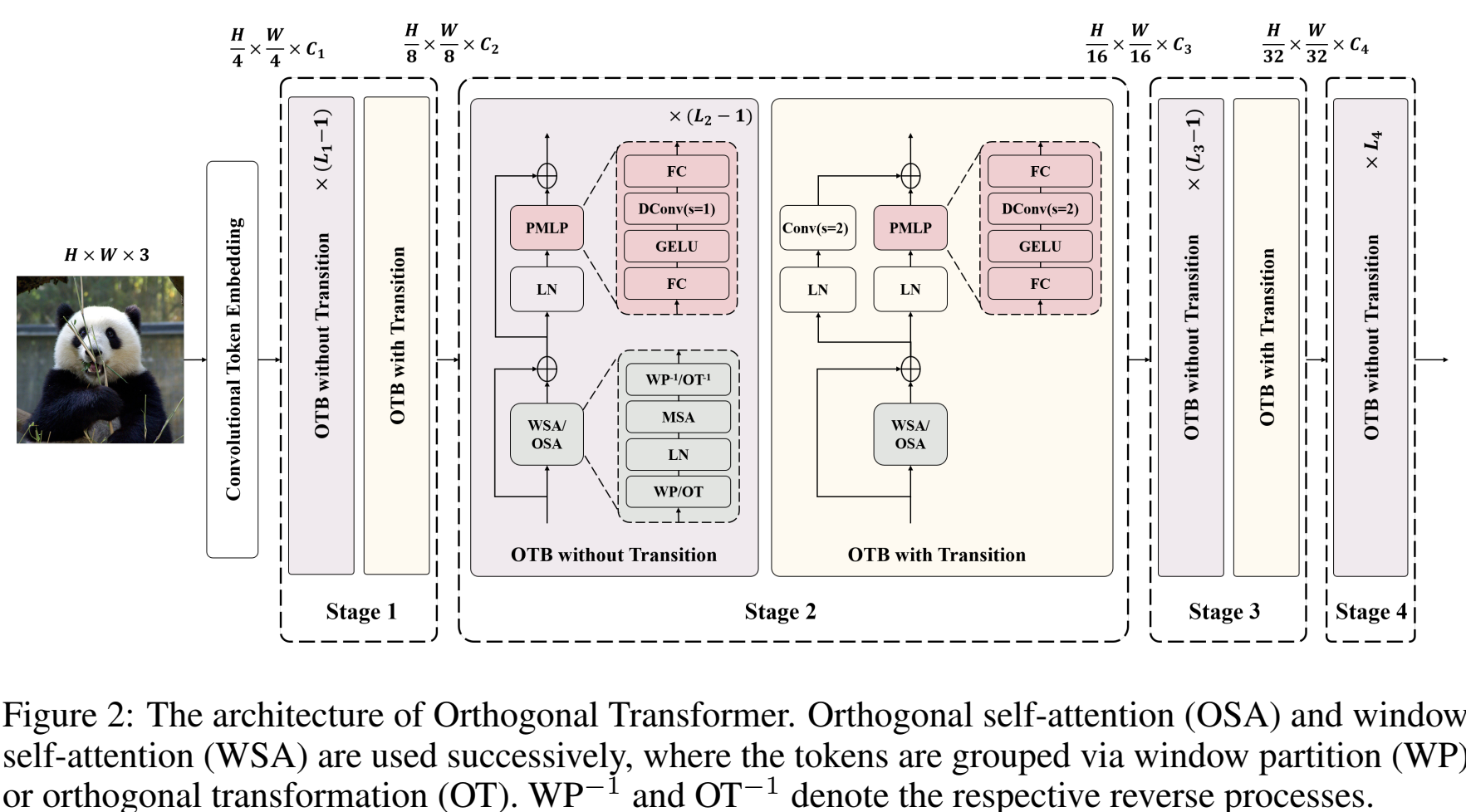
如图2所示,基于上述提出的正交自注意力机制,我们设计了一个高效视觉Transformer主干网络,称为正交Transformer。该网络1)采用层次化设计,共包含4个阶段,用于提取不同空间分辨率的图像特征。2)对输入采用卷积特征编码器,以获取更好的特征表示。3)在网络的中间部分,采用由正交自注意力机制构建的正交Transformer Block(OTB)。4)在前馈网络(FFN)中,采用了深度可分离卷积来融合位置信息。同时在每个阶段的最后一个OTB的前馈网络中,在残差连接层加入了步长为2的卷积,这样不仅可以避免额外引入块融合(Patch Merging)层,同时在实验中也被验证可以取得更好的效果。
Experiment
本文在图像分类、目标检测、语义分割和实例分割等任务上,与现有方法进行对比。图3展示了不同方法在ImageNet数据集上的分类精度,本文所提出的正交Transformer在所有任务上均取得了优异性能。轻量模型Ortho-T仅用0.7GFLOPs的计算量,就达到了74.0%的Top-1分类准确度,比现有工作提高2%以上。小模型Ortho-S仅使用CrossFormer-B的49%的GFLOPs计算量,便达到了和CrossFormer-B相同的分类准确率。在384分辨率的测试集上,大模型Ortho-L达到了85.4%的Top-1分类准确率,比Swin-B提高了1.2%,并且比CaiT-s48的计算量减少了约26%。其他任务上的更多实验结果请参看论文。
Conclusion
本文提出了一种新的高效视觉Transformer网络,称为正交Transformer。本文提出了正交自注意力机制,来同时建模全局特征依赖和局部特征相关性。同时,正交变换的过程是一种内生的、易于优化的变换形式,而无需引入额外的正则项约束。在图像分类、目标检测、实例分割和语义分割任务上,正交Transformer都取得了优异的性能。在未来的工作中,我们将进一步研究高效自注意力机制的其他设计方式,同时期待将正交Transformer应用到更多的计算机视觉任务中去。
Others
论文复现,一些想法、推论等等
References
如果对你有帮助的话,请给我点个赞吧~
欢迎前往 我的博客 查看更多笔记