Information
- Title: Semantic Image Synthesis With Spatially-Adaptive Normalization
- Author: Taesung Park, Ming-Yu Liu, Ting-Chun Wang, Jun-Yan Zhu
- Institution: UC Berkeley, NVIDIA, MIT CSAIL
- Year: 2019
- Journal: CVPR
- Source: Open access, Github
- Idea: 通过空间自适应归一化计算 norm 层的仿射变换参数
1 | @InProceedings{Park_2019_CVPR, |
Abstract
对于输入布局语义来合成逼真图像的网络,作者认为常规的 Normalization 层会“洗掉”语义信息,所以提出了使用输入布局来在 Normalization 层通过空间自适应来建模激活。
Introduction
作者使用的合成网络是基于 GAN 的对抗生成式网络,使用带有语义的 mask 图像来生成逼真的图片(从后面实验结果来看其实就是图像分割的逆过程)。
作者将 BN,IN,LN,WN 归类为无条件的 Normalization 因为它们不依赖于额外的数据,而 CBN(Conditional BatchNorm), AdaIN 等被归类为条件 Normalization,它们需要一些额外数据,和无条件的 Normalization 类似,先将其 norm 到 0 均值和单位方差,随后做一个仿射变换,但仿射变换的参数是由额外数据得到的。
作者提出的方法是针对空间信息的仿射变换,有另外一篇类似方法的论文:Recovering realistic texture in image super-resolution by deep spatial feature transform.
Method
作者提出的方法 SPADE 如下所示
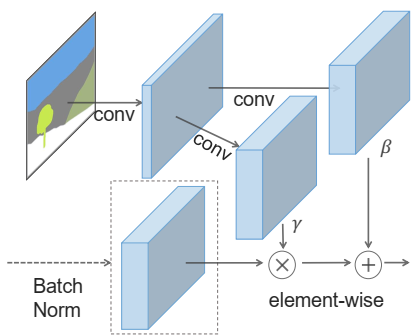
数学表达式为: $$ \gamma^i_{c,y,x}(\mathbf{m}) \frac{h^i_{n,c,y,x}-\mu^i_c}{\sigma^i_c} + \beta^i_{c,y,x}(\mathbf{m}) $$ 其中 (n ∈ N, c ∈ Ci, y ∈ Hi, x ∈ Wi),γ, β 在传统方法中是可学习参数,而这里使用函数形式表示将 m (m 是输入的 mask 语义图像)的一个映射,具体实现是一个简单的两层卷积网络 $$ \begin{align} \mu^i_c &= \frac{1}{N H^i W^i}\sum_{n,y,x} h^i_{n,c,y,x}\\ \sigma^i_c &= \sqrt{\frac{1}{N H^i W^i}\sum_{n,y,x} \Big( (h^i_{n,c,y,x})^2 - (\mu^i_c)^2 \Big) }. \end{align} $$ 从 m 提取的特征是空间不变的,如果吧 m 换成一个风格图片,那就和 AdaIn 是等价的了。
为什么 SPADE 有用呢?作者的解释是想不通用的Normalization层它能更好的保留语义信息,换而言之,就是如 IN 这样的规范层会把语义信息“洗掉”,作者举了一个极端一点的例子语义图像是完全相同的像素点,经过 IN 以后语义信息完全丢失了。相反,SPADE生成器中的语义图像是通过空间自适应机制的,没有规范化,只有来自前一层的激活才会被规范化。因此,SPADE生成器可以更好地保存语义信息。它具有规范化的好处,又不会丢失语义输入信息。
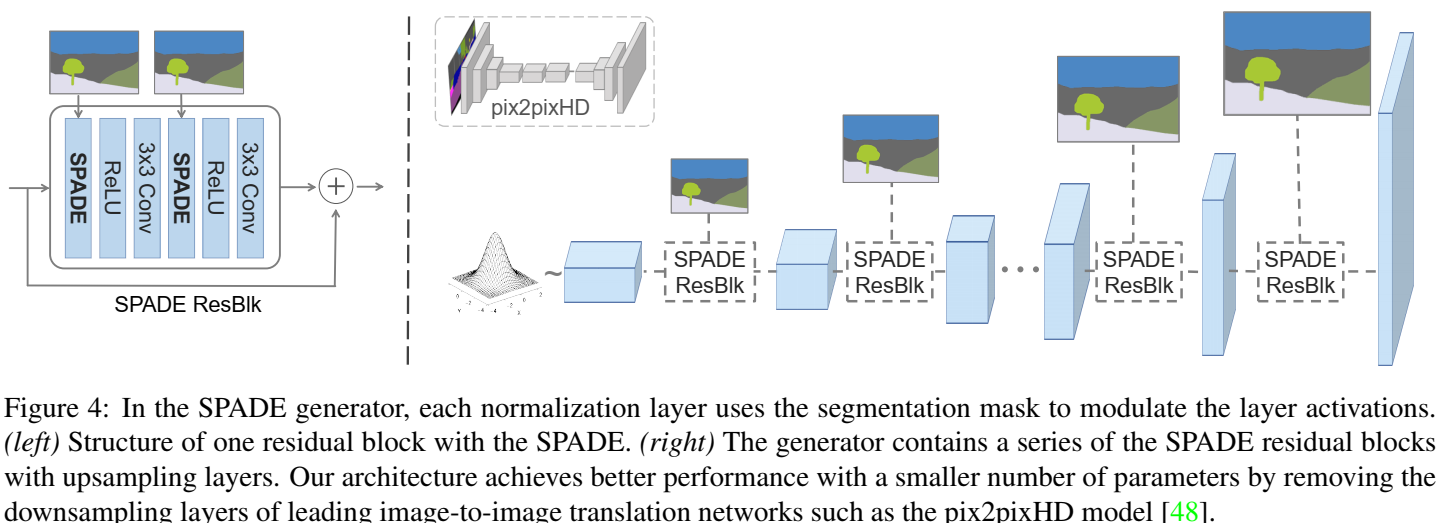
Detail
网络的一些细节
Experiment
略过,论文很多图,总的来说比以往的方法效果好一些,但一些精细的图像还是挺假的。

Conclusion
就是提出了空间自适应正则化方法,用于正则化层的仿射变换,使得模型能合成更真实的图像
Code
看看代码:
1 | # Creates SPADE normalization layer based on the given configuration |
初始化的部分挺多的,但实际上在 forward
部分流程很清楚,就是
- 先做一个无参数的 Normalize 的操作,这里看可以是不带仿射变换的 IN 或 BN
- 基于
segmap计算仿射变换的 γ 和 β, 具体计算可以看前面的,都是基于二维卷积的操作 - 将 γ 和 β 应用到仿射变换操作
如果对你有帮助的话,请给我点个赞吧~
欢迎前往 我的博客 查看更多笔记