Information
- Title: Dynamic Convolution: Attention over Convolution Kernels
- Author: Yinpeng Chen, Xiyang Dai, Mengchen Liu,
Dongdong Chen, Lu Yuan, Zicheng Liu
- Institution: 微软亚研院
- Year: 2022
- Journal: CVPR
- Source: Arxiv, open access
- Idea: 将多个卷积核通过注意力机制合成一个动态卷积核提高模型的表达能力
1 | @InProceedings{Chen_2020_CVPR, |
Abstract
提出了动态卷积,即将多个卷积核通过注意力机制聚合在一起来提高模型的表达性能。
Introduction
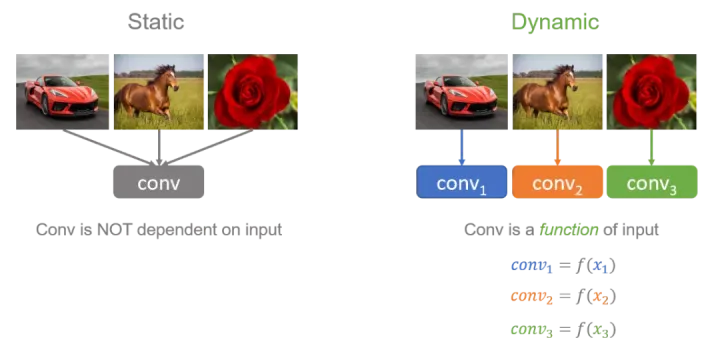
动态卷积的基本思路就是根据输入图像,自适应地调整卷积参数。如图1所示,静态卷积用同一个卷积核对所有的输入图像做相同的操作,而动态卷积会对不同的图像(如汽车、马、花)做出调整,用更适合的卷积参数进行处理。简单地来说,卷积核是输入的函数。
Method
动态卷积没有在每层上使用单个卷积核,而是根据注意力动态地聚合多个并行卷积核。注意力会根据输入动态地调整每个卷积核的权重,从而生成自适应的动态卷积。由于注意力是输入的函数,动态卷积不再是一个线性函数。通过注意力以非线性方式叠加卷积核具有更强的表示能力。
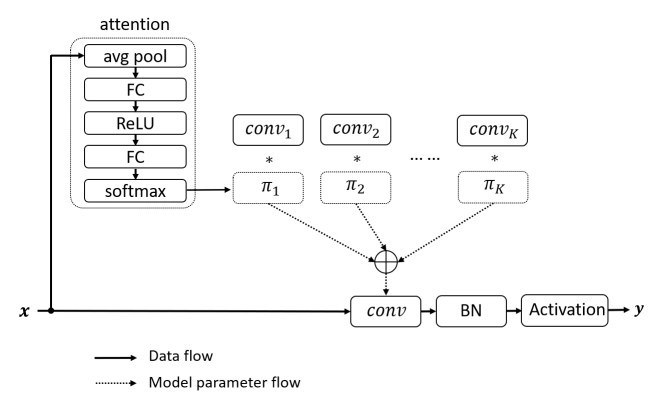
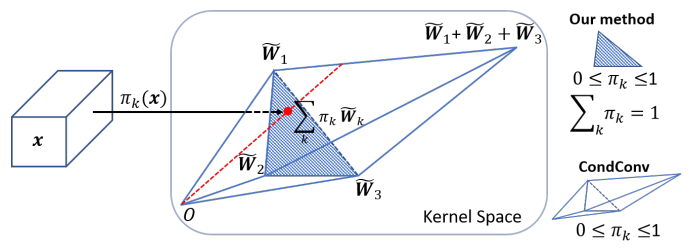
动态卷积网络的难点在于多个卷积核和注意力模型的共同学习。这个困难会随着网络深度的增加而增加。本文提出,解决这个问题有两个关键点。首先,限制注意力的取值将简化注意力模型的学习。注意力取值的限制将缩小多个卷积的叠加核的取值空间。文中将注意力取值限制在0与1之间,同时所有注意力的和为1。如图3所示,如果使用3个卷积核,注意力在0与1之间把叠加核限制在两个三棱锥中,注意力的和为1把叠加核进一步限制在以这三个卷积核为顶点的三角形中。对于这两个限制,softmax 是一个很自然的选择。
其次,限制注意力接近均匀分布有利于多个卷积核在训练初期同时学习。对于这个要求,softmax 就显得不那么合适了,因为 softmax 输出更稀疏的注意力。因此,温度(temperature)被引入到 softmax。接近均匀分布的注意力可以通过使用较大的温度来实现。文章也提到温度淬火(temperature annealing)有助于准确度的进一步提升,即 $$ \pi_{k} = \dfrac{\exp (z_k / \tau)}{\sum_j \exp (z_j / \tau)} $$
Detail
文章中论证了动态卷积的额外开销并不大,远远小于多个卷积并行的操作,并且效果也还不错
Experiment
主要是在 ImageNet 和 COCO 上的实验
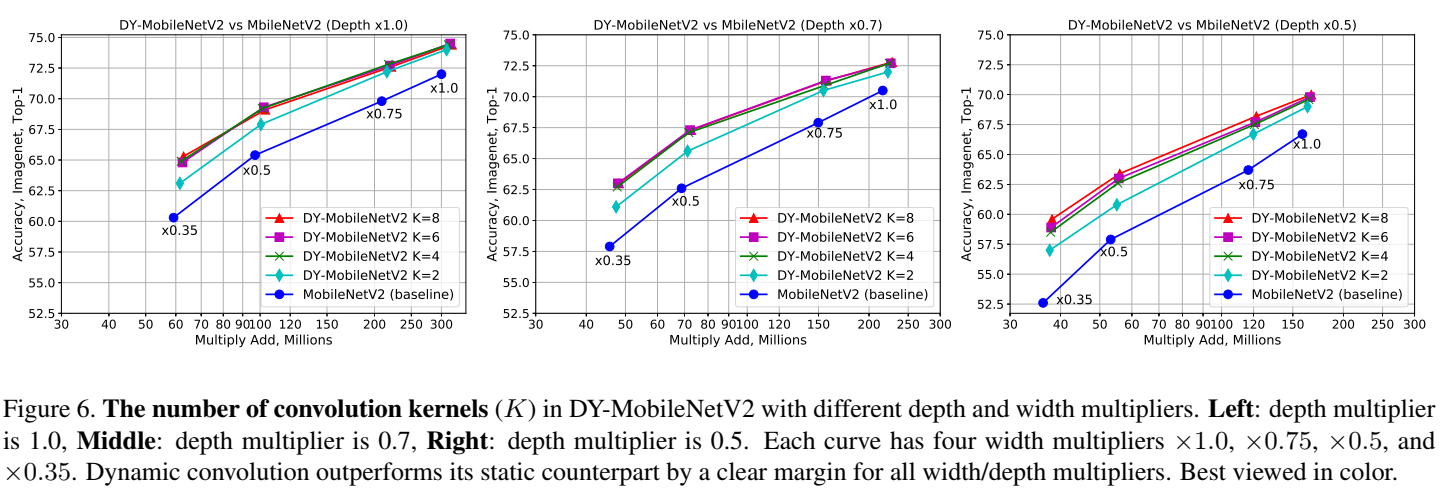

实验结果显示,动态卷积在 ImageNet 分类和 COCO 关键点检测两个视觉任务上均具有显著的提升。例如,通过在 SOTA 架构 Mobilenet 上简单地使用动态卷积,ImageNet 分类的 top-1 准确度提高了 2.3%,而 FLOP 仅增加了 4%,在 COCO 关键点检测上实现了 2.9 的 AP 增益。在关键点检测上,动态卷积在 backbone 和 head 上同样有效。
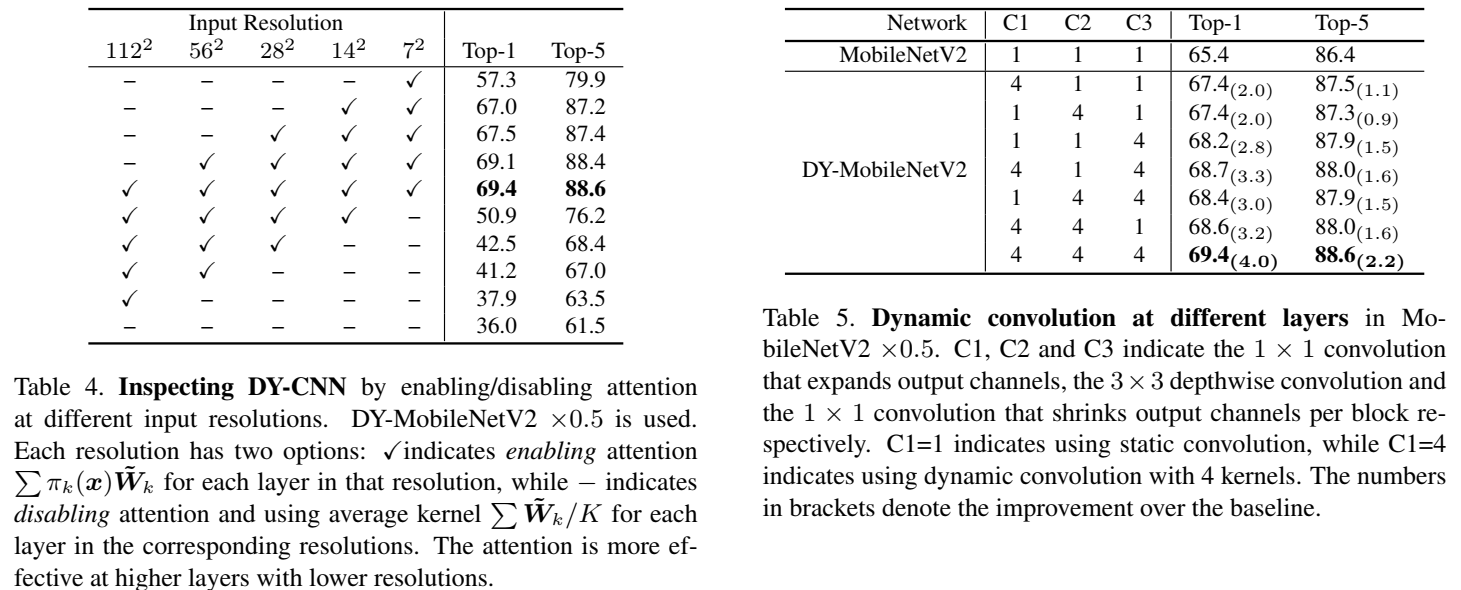
文章还对学习到的动态卷积进行了检测(inspection)来证实学到的卷积是不是真的动态。通过与多种静态叠加以及注意力的洗牌(shuffle)的对比,证实了注意力确实对不同的输入进行了动态调整。文中的对比试验也有一些有趣的发现,比如动态卷积在网络深层带来的提升明显高于浅层。同时,动态卷积在更浅或者更窄网络的提升更明显。
Conclusion
提出了基于注意力机制的动态卷积,带来了显著的效果提升而没有很大的计算开销,并且能很容易的用到现有的卷积神经网络结构
Others
没开源代码
References
如果对你有帮助的话,请给我点个赞吧~
欢迎前往 我的博客 查看更多笔记