Information
- Title: Facial Expression Recognition in the Wild via Deep Attentive Center Loss
- Author: Amir Hossein Farzaneh and Xiaojun Qi
- Institution: Department of Computer Science Utah State University Logan, UT 84322, USA (美国犹他州立大学)
- Year: 2021
- Journal: WACV
- Source: PDF, Offical code
- Idea: 利用注意力机制给稀疏中心损失加权
1 | @InProceedings{Farzaneh_2021_WACV, |
Abstract
针对的问题:度量学习中平等的监督包括一些不相关的特征在内的所有特征会降低模型的泛化性能。
给出的解决方案:提出 DACL(Deep Attentive Center Loss) 自适应选择显著的特征元素
Introduction
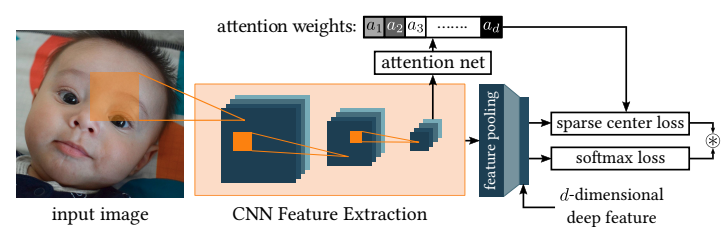
利用卷积层提取的特征估计注意力权重,用于指导稀疏中心损失模块使类内靠近和类间远离。
Method
(这篇文章没有paper源码,就不敲公式了,简单总结一下)所谓中心损失就是每个样本到聚类中心的聚类之和(WCSS, Within Cluster Sum of Squares),作者认为这其中有些特征对于我们的目标来说是不重要的,所以对样本通过 CNN 提取的 d 维特征与中心的距离进行一个加权操作,而权重是由注意力机制得到的。
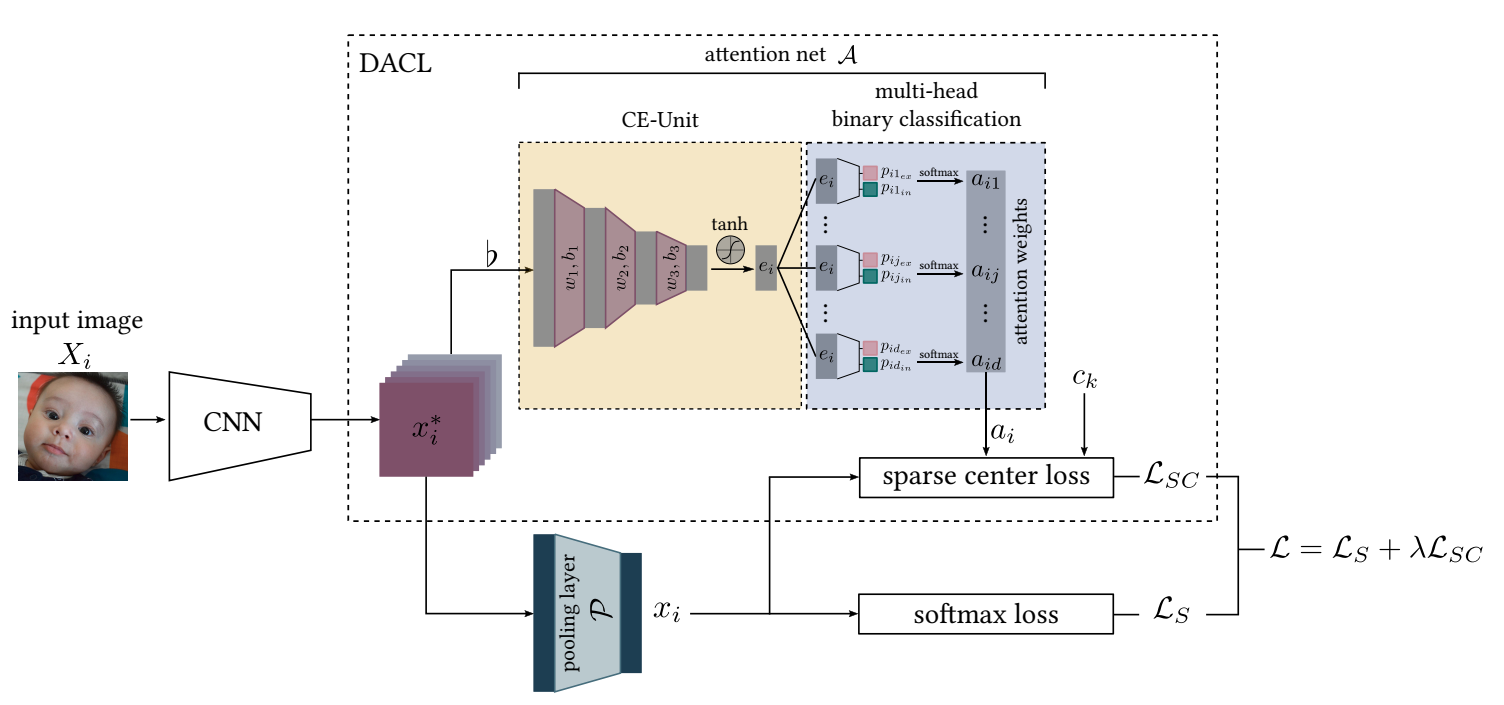
如图,ℒs 是一个常规的分类损失,而上面虚线框中的就是作者提出的方法,其中 xi* 是通过 CNN 网络提取的一个 d 维的特征,在 CE-Unit 中提取相关信息 ei,然后在多头分类器中计算权重,最后对稀疏中心损失进行加权操作。思路其实不是很复杂,但这里还有一个很关键的点就是这个注意力网络 𝒜 是怎么设计的。
注意力网络 𝒜 包含了两个模块
- 上下文编码单元(Context Encoder Unit, CE-Unit),以 CNN 提取的特征图作为上下文生成隐含特征,主要是三个全连接层:flatten → fc → BN → relu → fc → BN → relu → fc → BN → tanh.
- 多头二元分类器,将 CE-Unit 的隐含特征作为输入估计注意力权重,每个头会输出两个分数,一个是包含重要特征的分数,一个是不包含;然后取包含的softmax 计算结果作为最终的权重。
Experiment
用了 RAF-DB 和 AffectNet 两个数据集,和在 MS-CELEB-1M 上预训练的 Resnet18 作为backbone。具体结果可以看原文,其实对比中心损失的方法改进只是有一点改进,改进不是特别大,两个数据集上都是提升了 1% 的样子。
Conclusion
DACL 是一种通过注意力机制来自适应控制在深度度量学习中特征表达的强度的方法。此外,由可自定义的神经网络完全参数化的注意力机制通过为稀疏中心损失提供注意力权重来估计所有维度的贡献概率。
确实是有效果的,但感觉这附加的参数量和提高的效果有点得不偿失,因为显然注意力网络不算小,但提升有限,但思路还是值得参考的。
Others
代码解析
模型部分 可见确实是计算量极大,第一个 fc 层有千万级别的参数
1 | class ResNet(nn.Module): |
损失函数
1 | criterion = { |
所以关键在这个损失函数这里,但下面的代码不算特别懂
1 | import torch |
References
如果对你有帮助的话,请给我点个赞吧~
欢迎前往 我的博客 查看更多笔记