Information
- Title: Gradient Normalization for Generative Adversarial Networks
- Author: Yi-Lun Wu, Hong-Han Shuai, Zhi Rui Tam, Hong-Yu Chiu
- Institution: (台湾)國立交通大學
- Year: 2021
- Journal: ICCV2021
- Source: arxiv, open access, pdf, Official Code
- Idea: 提出了GN对整个模型进行Lipschitz约束来提高GAN训练的稳定性
- Cite: Yi-Lun Wu, Hong-Han Shuai, Zhi-Rui Tam, Hong-Yu Chiu; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 6373-6382
1 | @InProceedings{GNGAN_2021_ICCV, |
Abstract
文章提出了一种通用的 Gradient Normalization(GN) 的方法来解决生成对抗网络(GANs)中由尖锐梯度空间导致的训练不稳定的问题。GN 仅在鉴别器上增加了对梯度范数约束来提高鉴别器的性能。
Introduction
GAN 的评价指标: FID 和 IS 参考: https://blog.csdn.net/qq_35586657/article/details/98478508
GAN 包含两个网络:生成器(目标是生成可以骗过鉴别器的图片),鉴别器(目标是鉴别出生成器生成的图片)。GANs 的一个挑战性的问题是训练过程不稳定,其中一个原因是鉴别器的尖锐梯度空间(sharp gradient space)导致生成器模型崩塌。简单的处理方法是 L2 规范化和权重裁剪,但这种处理方法会导致鉴别器的性能下降。另一种方法是对鉴别器通过正则化和规范化约束Lipschitz连续函数小于一个固定的Lipschitz常数 K, 可以在不牺牲鉴别器性能的条件下平滑梯度空间。
作者认为可以从三个角度考察Lipschitz约束:
- 约束模块还是模型,约束模型的好些,因为约束模块会降低单个模块性能
- 基于采样的还是非基于采样的,如果方法需要从固定的分布进行采样,那就是基于采样的,非采样的好些,基于采样的可能遇到“新样本”时不那么有效
- 严约束还是松约束,定义是梯度范数是否小于一个有限的固定值,严约束更好因为可以避免未见过的样本导致梯度不稳定
目前还没有同时满足约束模块,非采样,严约束的方法,但作者提出的方法 GN 就同时满足,并且很容易迁移到不同类型的网络结构中。
这篇文章的三点贡献:
- 针对 GAN 提出了 GN 很好的平衡了训练过程的稳定性和生成器的性能
- 从理论上证明了 GN 是梯度范数有界的,该性质可以避免生成器遇到梯度爆炸梯度消失的问题并且稳定训练过程
- IS 和 FID 评价的实验结果 SOTA
相关工作
主要提到有两类:正则化(regularization), 规范化(Normalization)
- 正则化:主要是对尖锐梯度进行约束,有基于梯度惩罚的方法,Lipschitz 正则化、一致性约束、正交约束等
- 规范化:例如基于谱范数的规范化、基于权重范数的规范化等。注意到规范化都是非采样的,在训练稳定性上会比正则化更优
$$ D_{KL}(p||q) = \sum_{i=1}^{N} p(x_i)\cdot log\frac{p(x_i)}{q(x_i)} $$
对于 Wasserstein loss 和 WGAN 讲解比较清晰的一篇文章: https://zhuanlan.zhihu.com/p/25071913
及其后续有提到权重裁剪和梯度惩罚:https://www.zhihu.com/question/52602529/answer/158727900
Lipschitz 约束在 GAN 中的作用
对于输入为x的判别器网络可以表示为:
f(x, θ) = WL + 1aL(WL(aL − 1(WL − 1(⋯a1(W1x)⋯))))
其中,θ := {W1, ⋯, WL, WL + 1}是学习参数集,也就是网络的权重,al是非线性激活函数,上述表达式没有考虑偏差。 完整的判别器网络可以表示为:
D(x, θ) = 𝒜(f(x, θ)) 对于GAN而言,判别器的目的是为了区分开真假样本,要最大化目标函数maxDV(G, D),在固定生成器后得到的判别器最优解为:
$$ D_G^*(x) = \frac{q_{data}(x)}{q_{data}(x) + p_G(x)} = sigmoid(f^*(x)) $$ 我们知道sigmoid的表达式为$\frac{1}{1+e^{-x}}$代入上式可以解出:
f*(x) = logqdata(x) − logpG(x) 我们对f*(x)对x求导:
$$ \nabla_x f^*(x) = \frac{1}{q_{data}(x)} \nabla_x q_{data}(x) - \frac{1}{p_G(x)} \nabla_x p_G(x) $$ 这个导数可以是无限的,甚至是无法计算的,这就会造成判别器失控(一路无限制优化),导致函数空间很大,这就使得D的能力过强,GAN的平衡倾斜。 为了给予判别器于一定限制,这就要Lipschitz假设,通过添加在输入示例x上定义的正则化项来控制鉴别器的Lipschitz常数,此时优化就为:
argmax‖f‖Lip ≤ KV(G, D)
自此,我们看到Lipschitz假设对于GAN的重要性,为了较好实现Lipschitz假设,谱归一化将展示强大的能力。
Method
GAN
基本的GAN网络包含生成器和判别器,数学表述为
生成器 G : ℝdz → ℝn, 判别器 D : ℝn → ℝ, 最小最大化目标是 $$ \begin{aligned} \min_G\max_D\text{ }&\mathbb{E}_{x\sim p_r(x)}\big[log(D(x))\big]+\mathbb{E}_{\tilde{x}\sim p_g(x)}\big[log(1-D(\tilde{x}))\big] \end{aligned} $$ 其中 pr(x) 表示真实数据分布, pg(x) 表示由 pg = G*(pz) 定义的分布(* 表示前推测度 , pz 是 dz 维的先验分布)。
前推测度(pushforward measure) 参考 https://en.wikipedia.org/wiki/Pushforward_measure, 大概理解下就是……我不理解 😳
但这里的意思就是 pg(x) 表示生成样本,整体的思路就是判别器要尽可能把真实样本分为正例,生成样本分为负例,𝔼 表示期望,而生成器的目标相反,尽量使分类器无法区分真实样本和生成样本
GAN很难训练,问题包括但不仅限于梯度消失和梯度爆炸,主要产生的原因是:
- 优化的目标函数等级与最小化 pg(x) 和 pr(x) 的 JS 散度,而当 pg(x) 和 pr(x) 没有交集的时候 JS 散度是一个常数,梯度为 0
- 有限的样本容易是判别器过拟合间接导致梯度爆炸
WGAN 提出了一种新的损失函数 minGmaxD, LD ≤ 1 𝔼x ∼ pr(x)[D(x)] − 𝔼x̃ ∼ pg(x)[D(x̃)], LD := inf {L ∈ ℝ : |D(x) − D(y)| ≤ L‖x − y‖, ∀x, y ∈ ℝn} 表示判别器的 Lipschitz 常数,等价于 |D(x) − D(y)| ≤ LD‖x − y‖, ∀x, y ∈ ℝn. (具体可以看前面提到的那篇文章,讲得很详细)
不过,限制神经网络的Lipschitz常数和提高神经网络的性能之间很难达到一个平衡,有些方法直接对每层的Lipschitz常数进行限制,导致网络的函数空间受到了限制影响性能,而权重裁剪和正则化的方法虽然可以在一个更大的空间内进行搜索,但限制却很弱。
接下来,作者证明了逐层Lipschitz限制网络的Lipschitz常数的上界由其第一个 k 层子网络的任意一层决定。
证明和推导
定义1 用 fK : ℝn → ℝ 表示一个 K 层网络,该网络可以描述为一系列的仿射变换的嵌套 $$ \begin{aligned} f_K(x)&=\phi_K(\mathbf{W}_K\cdot(\phi_{K-1}(\cdots \mathbf{W}_1\cdot x+\mathbf{b}_1))+\mathbf{b}_K)\\ &=\phi_K(\mathbf{W}_K\cdot f_{K-1}(x)+\mathbf{b}_K), \end{aligned} $$ 其中 WK ∈ ℝdK × dK − 1 和 bK ∈ ℝdK 是第 K 层的网络参数, dK 是目标维度, ϕK 是第 K 层的非线性激活函数,用 fk, ∀k ∈ {1⋯K} 表示第一个 K 层子网。
定义2 用 fK : ℝn → ℝ 表示一个 K 层网络,令 ∃Lk ≤ L, ∀k ∈ {1⋯K} 则 fK 表示一个表示一个逐层 L-Lipschitz 现在的网络,LK 是第 K 层的 Lipschitz 常数: ‖Wk ⋅ x − Wk ⋅ y‖ ≤ Lk‖x − y‖, ∀x, y ∈ ℝdk − 1. 引理3 f : ℝn → ℝ 是连续可微函数,Lf 是 f 的 Lipschitz 常数,则 Lipschitz 限制 |f(x) − f(y)| ≤ Lf‖x − y‖, ∀x, y ∈ ℝn 等价于 ‖∇xf(x)‖ ≤ Lf, ∀x ∈ ℝn
引理3 的证明:
先证充分性:
由 Lipschitz 限制的定义可知 |f(x) − f(y)| ≤ Lf‖x − y‖ 我们考虑 x 在 (y − x) 方向的方向导数的范数 $$ \langle\nabla f(x),\frac{y-x}{\Vert y-x\Vert}\rangle=\lim_{y\rightarrow x}\frac{\vert f(y)-f(x)\vert}{\Vert x-y\Vert}\le L_{f} $$ 其中 ⟨⋅, ⋅⟩ 表示内积,因此梯度的范数是最大的方向导数范数,因此 ‖∇f(x)‖ ≤ Lf 充分性得证,下面证必要性:
根据假设,f 是连续可微的,满足梯度定理条件,因此可以只考虑 y 到 x 的直线的线积分 $$ \begin{align} &\vert f(x)-f(y)\vert\\ &=\Big\vert\int_y^x\nabla f(r) dr\Big\vert\\ &=\Big\vert\int_0^1\langle \nabla f(xt+y(1-t)),x-y\rangle dt\Big\vert\\ &\le\Big\vert\int_0^1\Vert \nabla f(xt+y(1-t))\Vert\cdot\Vert x-y\Vert dt\Big\vert\\ &\le L_{f} \Big\vert\int_0^1\Vert x-y\Vert dt\Big\vert\\ &=L_{f}\Vert x-y\Vert. \end{align} $$ 因此必要性得证。
引理 3 启发作者设计一种直接约束梯度范数的规范化方法。
假设4 f : ℝn → ℝ 表示由神经网络定义的连续函数,且 f 的所有激活函数都是分段线性的,因此 f 也是近乎可微的。
定理5 fK : ℝn → ℝ 表示一个逐层 1-Lipschitz 约束的 K 层网络,第一个 k 层网络的 Lipschitz 常数上限 Lfk 由 Lfk − 1 决定,即: Lfk ≤ Lfk − 1, ∀k ∈ {2⋯K}
证明:
因为所有层都包含了激活函数且都是 1-Lipschitz 约束,那么 $$ \begin{aligned} \Vert \mathbf{W}_k\cdot x-\mathbf{W}_k\cdot y\Vert&\le\Vert x-y\Vert,\forall x,y\in\mathbb{R}^{d_{k-1}}\\ L_{\phi_k}&=1. \end{aligned} $$ 由上式我们可以推出第 k 层的特征距离上限: $$ \begin{aligned} &\Vert f_k(x)-f_k(y) \Vert \\ &=\Vert\phi_k(\mathbf{W}_k\cdot f_{k-1}(x)+\mathbf{b}_k)-\phi_k(\mathbf{W}_k\cdot f_{k-1}(y)+\mathbf{b}_k)\Vert \\ &\le L_{\phi_k}\Vert(\mathbf{W}_k\cdot f_{k-1}(x)+\mathbf{b}_k)-(\mathbf{W}_k\cdot f_{k-1}(y)+\mathbf{b}_k)\Vert \\ &\le L_{\phi_k}L_k\Vert f_{k-1}(x)-f_{k-1}(y)\Vert \\ &= \Vert f_{k-1}(x)-f_{k-1}(y)\Vert. \\ \end{aligned} $$ 即 $$ \frac{\Vert f_k(x)-f_k(y)\Vert}{\Vert x-y\Vert}\le\frac{\Vert f_{k-1}(x)-f_{k-1}(y)\Vert}{\Vert x-y\Vert}, \forall x,y \in\mathbb{R}^n $$ 证毕
定理5当且仅当 ∃x, y ∈ ℝn 且满足下式时成立 $$ \frac{\Vert f_k(x)-f_k(y)\Vert}{\Vert x-y\Vert}=\frac{\Vert f_{k-1}(x)-f_{k-1}(y)\Vert}{\Vert x-y\Vert}=L_{f_{k-1}} $$ 否则 Lfk < Lfk − 1 < ⋯ < Lf1 ≤ 1 即 Lipschitz 常数逐层减小,另一方面,也不必逐层Lipschitz约束,而是可以构建整个Lipschitz模型。根据引理 3,作者提出了 Gradient Normalization (GN).
GN 对梯度范数 ‖∇xf(x)‖ 进行规范化且同时限制了 f(x) : $$ \hat{f}(x)=\frac{f(x)}{\Vert\nabla_x f(x)\Vert+\zeta(x)} $$ 其中 ζ(x) : ℝn → ℝ 是一个通用项,可以是常数或者与 f(x) 相关避免 |f̂(x)| 变成无穷大或 ‖∇xf̂(x)‖ 近乎0. 作者将 ζ(x) 设置为 |f(x)| 并证明 GN 是满足 1-Lipschitz 约束
定理6 将 f : ℝn → ℝ 定义为有神经网络建模的连续函数,并且网络中的所有激活函数都是分段线性的。规范化函数 f̂(x) = f(x)/(‖∇xf(x)‖+|f(x)|) 是梯度范数的界限,因为 $$ \Vert\nabla_x\hat{f}(x)\Vert=\Bigg\vert\frac{\Vert\nabla f\Vert}{\Vert\nabla f\Vert+\vert f\vert}\Bigg\vert^2\le 1 $$
证明:
简单起见,这里忽略函数参数。由 f̂(x) 的梯度范数定义得: $$ \begin{align} \Vert\nabla\hat{f}\Vert &=\Bigg\Vert\nabla\bigg(\frac{f}{\Vert\nabla f\Vert+\vert f\vert}\bigg)\Bigg\Vert \\ &=\Bigg\Vert\frac{\nabla f\big(\Vert\nabla f\Vert+\vert f\vert\big)-f\nabla\big(\Vert\nabla f\Vert+\vert f\vert\big)}{\big(\Vert\nabla f\Vert+\vert f\vert\big)^2}\Bigg\Vert. \label{th5:pfeq2} \end{align} $$ 由链式规则,可以推出 $$ \begin{align} \nabla\Vert\nabla f\Vert&=\nabla^2 f\frac{\nabla f}{\Vert\nabla f\Vert}, \\ \nabla\vert f\vert&=\nabla f\frac{f}{\vert f\vert}. \end{align} $$ 由于神经网络中的激活函数都是分段线性的,所以其 Hessian 矩阵 ∇2f 是 0 矩阵,前面的式子可以化简为 $$ \begin{aligned} \Vert\nabla\hat{f}\Vert =\Bigg\Vert\frac{\Vert\nabla f\Vert^2}{\big(\Vert\nabla f\Vert+\vert f\vert\big)^2}\Bigg\Vert =\Bigg\Vert\frac{\Vert\nabla f\Vert}{\Vert\nabla f\Vert+\vert f\vert}\Bigg\Vert^2\le 1. \end{aligned} $$ 即定理 6
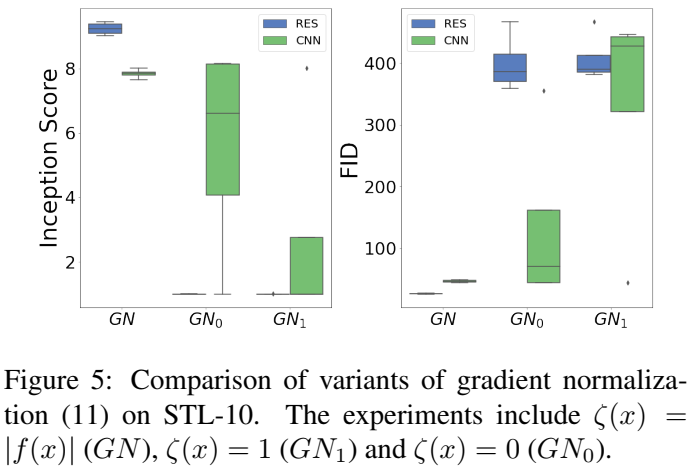
考虑到如果鉴别器过拟合可能会出现 f(x) → ±∞ 和 ‖∇xf(x)‖ → 0 的情况,以及 ζ(x) = 0 和 ζ(x) = 1 两种常见情况。

因为函数范数 |f(x)| 不直接与梯度范数相关,所以对于极端预测结果可能是规范化的梯度范数‖∇xf̂(x)‖ 和规范化的函数值 |f̂(x)| 爆炸,所以提出将 ζ(x) 设置为 |f(x)| 。这种自动调整的机制能防止生成器获得爆炸梯度,以此可以稳定GAN的训练过程。伪代码如下:

GN的梯度分析: f̂(x) 对 Wk 的的梯度如下: $$ $$ 从最后一个等式可以看出,GN 是自适应梯度正则化的特殊形式。而第一个等式中,第一项是GAN的目标梯度,用于提高鉴别器的性能,而第二项是正则项,用自适应的正则化参数惩罚 f 的梯度范数。这种梯度惩罚更灵活,因此这种自平衡机制强迫GN达到严 Lipschitz 约束。
Experiment
- 数据集:
- CIFAR10: 包含 60K 大小为 32 × 32 × 3 的图像,划分为 50K 训练集和 10K 测试集
- STL-10:无监督数据集,48 × 48 × 3, 包含 5k 训练数据,8k 测试数据和 100k 无标签数据
- CelebA-HQ: 超分辨率数据集, 30k 大小为 256 × 256 × 3 人脸图像
- LSUN Church Outdoor:超分辨率数据集, 包含 126k 大小为 256 × 256 × 3 的教堂户外景象
- 验证标准:Inception Score (IS)和 Frechet Inception Distance (FID)
- 损失函数:因为 GN 的输出为 [−1, 1]
会使 Wasserstein loss 退化为 hinge loss
- hinge loss
- nonsaturating loss (NS)
无条件图像生成
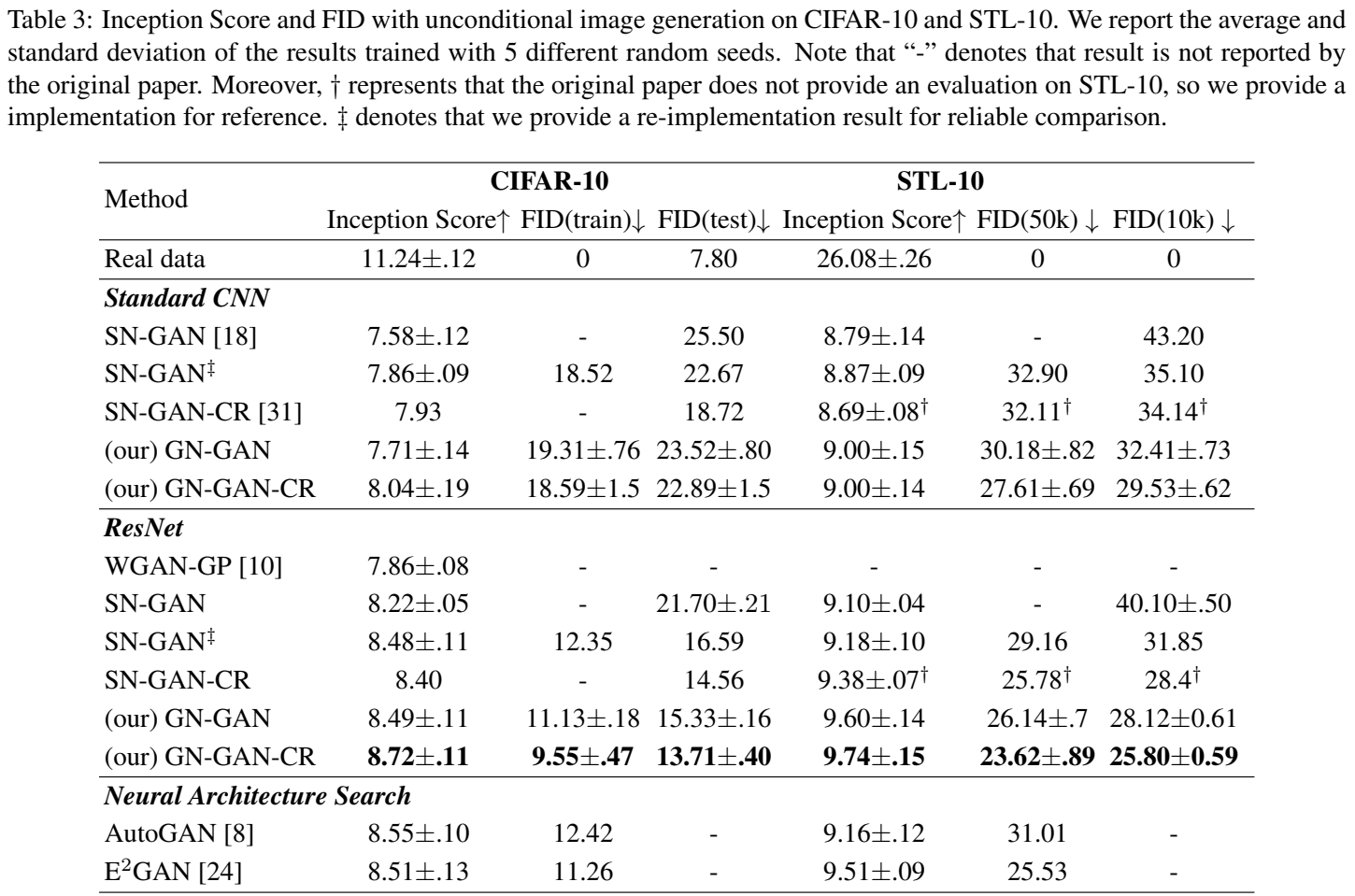
GN-GAN 联合 consistency regularization (CR) 标记为 GN-GAN-CR
有条件图像生成

无条件大尺寸图片生成

附加材料有更多的图片展示
定理5的实验分析
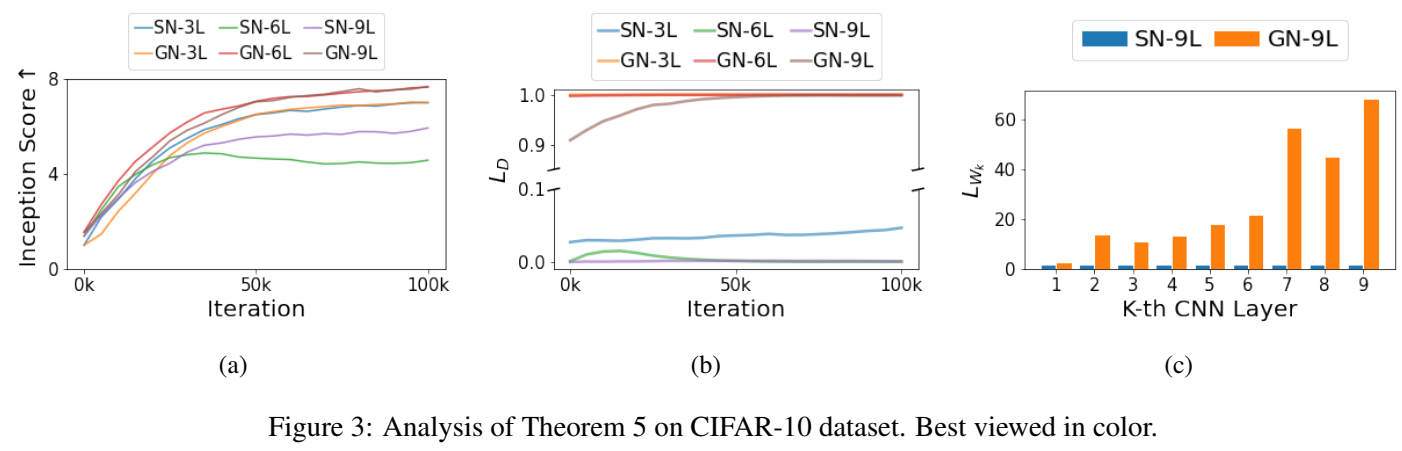
根据定理5,随着层数增加,Lipschitz常数减小。上图展示了对 SN 和 GN 使用 wasserstein loss 的测试,nL 表示生成器和鉴别器的卷积层的数量,可见SN的鉴别器Lipschitz常数远小于1. 此外,SN-GAN 的所有鉴别器在Lipschitz约束LD ≤ 1下都不能很好地近似的 Wasserstein 距离,即使上述推论保证了最优鉴别器的存在,作者认为这是因为SN过度约束了鉴别器的Lipschitz常数以至于鉴别器无法提高Lipschitz常数并接近理论最优。
消融实验
激活函数 定理6的前提是激活函数是分段线性的,作者测试了不同激活函数下的效果对比
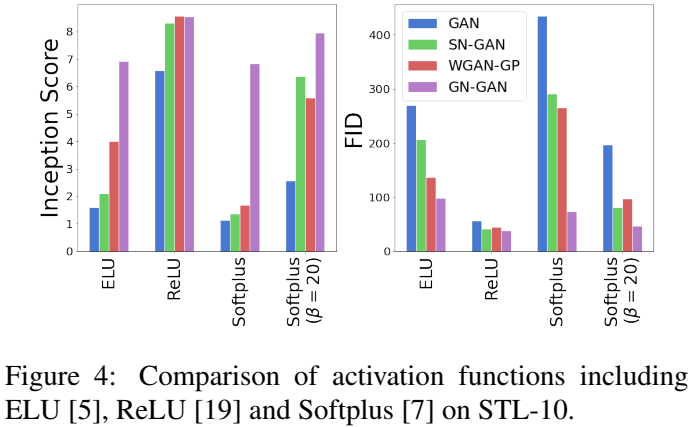
GN变量 如图所示
Conclusion
提出了一种简单实现的梯度规范化方法GN用于稳定GANs的训练,并证明了其满足严Lipschitz约束并使任意鉴别器作为Lipschitz连续函数。实验中在不同结构的网络和不同数据集中取得了SOTA结果。
作者计划后续用类似的方法替换GN的分母来减少计算量,还有就是在一些其他生成任务。
Code Analysis
开源代码仓库中提到 GN 任意迁移到其他 GAN 网络结构中,
1 | from torch.nn import BCEWithLogitsLoss |
关键代码在第 20 行
pred_fake = normalize_gradient(net_D, x_fake) # net_D(x_fake),我们进入函数内部查看,函数实现仅8行
1 | def normalize_gradient(net_D, x, **kwargs): |
从前面的代码中我们可以了解到,函数声明中的两个参数 net_D
和 x
分别是鉴别器网络和生成器生成的图片,下面逐行分析代码
- 第 7, 8 行: 将 x 的梯度计算打开,然后传入鉴别器中进行前向传播
- 第 9, 10 行: 计算鉴别器输出对输入图像的导数
- 第 11 行:将梯度值展平为二维并计算范数,实际上展平操作有些多余了,和
torch.norm(grad, p=2, dim=(1, 2, 3))是等价的 - 第 12 行:调整梯度范数
- 第 13 行:GN操作
在解读代码之前,我以为GN是针对网络权重进行规范化的,在看完代码后,GN实质上还是对特征进行规范化,但GN没有改动特征图,而是只对网络的输出进行规范化来达到限制网络的Lipschitz常数的作用,这是一个值得借鉴的思路
GAN
训练
借此机会分析一下 GAN 的训练过程,给代码加了详细的注释,据此对 GAN 网络的训练有了更深的了解
1 | def train(): |
验证
1 | def generate_images(net_G): |
损失函数
看看一些损失函数的实现
1 | import torch |
References
- 生成对抗网络(GAN)
- SN-GAN论文解读
- 详细解析深度学习中的 Lipschitz 条件
- GAN的几种评价指标
- 令人拍案叫绝的Wasserstein GAN
- 详解 pytorch 中的 autograd.grad() 函数
如果对你有帮助的话,请给我点个赞吧~
欢迎前往 我的博客 查看更多笔记