Information
- Title: CrossNorm and SelfNorm for Generalization under Distribution Shifts
- Author: Zhiqiang Tang
- Institution: Amazon Web Services
- Year: 2021
- Journal: ICCV
- Source: ICCV 2021 open access, arxiv
- Code: Official implementation
- Idea: 对 feature map 通道的均值和方差做交换以提高泛化性鲁棒性
1 | @InProceedings{Tang_2021_ICCV, |
Abstract
传统的归一化方法通常假设训练集和测试集同分布,但在现实世界中分布偏移(distribution shifts)是很常见的,这导致在训练好的模型在一些新场景表现很差。在该文章中提出了 CrossNorm 和 SelfNorm 两个方法来提高泛化性鲁棒性。CrossNorm 交换 feature maps 的通道均值方差来扩大训练集分布,SelfNorm 使用注意力来重新校准训练集和测试集分布的统计差距。尽管两种方法方向不同,但彼此之间可以互补。
Introduction
所谓分布偏移(distribution shifts)举个 :chestnut: 在一个城市中训练的驾驶模型放到另外一个城市可能就不好用了。
作者解释了为什么 Normalization 的方法在分布偏移中可以提升泛化性。其基本的思路包括两种:扩大训练集的分布和缩小测试集的分布。
首先,扩大训练集的分布其实是一种数据增强的方法,并不符合传统 Normalization 稳定和加速训练的目标。其灵感来源于观察到交换两张图片的 RGB 通道的均值和方差能产生风格迁移的效果,如 图1(a) 所示。由通道均值和方差编码的风格例如物体形状通常在识别任务中不太重要,所以改变风格也不用担心影响标签。据此作者提出了 CrossNorm。
SelfNorm 的灵感来源于一个类似的现象:调整图片 RGB 通道的均值和方差能减少图片风格的差异,如 图1(b) 所示。通过调整通道均值和方差,可以缩小测试集的分布,使得训练集和测试集的风格更加一致。

看起来 CrossNorm 和 SelfNorm 操作似乎是相反的,CrossNorm 旨在进行风格强化,而SelfNorm旨在进行风格统一(style recalibration),但两者的实现方式(修改通道统计量)和目标(提高泛化性和鲁棒性)基本相同。此外,CrossNorm 可以对 SelfNorm 进行增强,CrossNorm 可以让 SelfNorm 使用更多不同风格的样本进行训练。
总的来说,这篇文章有三点重要的贡献:
- 提出了一种与传统 Normalization 不一样的方向:在分布偏移的条件下使用 Normalization 提高泛化性
- 提出了 CrossNorm 和 SelfNorm 这两种互补的方法用于提高泛化性和鲁棒性
- CrossNorm 和 SelfNorm 的鲁棒性能在不同领域都能达到 SOTA
Method
相关工作对比
合成分布偏移下的泛化性
合成分布偏移主要指对已有图片进行一些修改得到偏移测试集。包括对抗样本(Adversarial examples)、图像破坏(image corruptions)等。而在这方面的研究有Stylized-ImageNet, AugMix, Adversarial noises training(ANT), unsupervised domain adaptation.
对比 Stylized-ImageNet[1], CrossNorm 直接在目标 CNNs 的特征空间上进行更有效的风格迁移,而 Stylized-ImageNet 需要额外的风格数据集和预训练的风格迁移模型。其次,CrossNorm 在清晰的和损坏的(corrupted)数据上都能提高性能,而 Stylized-ImageNet 会损伤清晰图像的泛化性因为额外的风格会导致更大的训练分别偏移。
此外,CrossNorm 和 Augmix, ANT 互不干扰,可以协同工作。
自然分别偏移下的泛化性
自然分布偏移是相对合成分布偏移定义的,指没有修改过的数据。典型的例子是视频,相邻的帧在人类看起来差别不大但深度模型却得到了不一样的结果。解决的方法有 IBN[2], Domain randomization[3], 后者与 Stylized-ImageNet 有着同样的问题,即需要预训练数据和预训练模型。
相比之下,SelfNorm 通过风格统一打通了分布鸿沟(distribution gaps), 而 CrossNorm 更有效更均衡的沟通了源数据集和目标数据集的性能。
Normalization和Attention
有一些将注意力用到多种 Normalization 中的方法,SelfNorm 仅仅是将注意力用到 Instance Normalization 中,使得 SelfNorm 更关注重要的风格而抑制琐碎的风格,减少了因风格差异导致的分布鸿沟。
数据增强
目前的数据增强方法主要包括标签保护(label-preserving)和标签扰动(label-perturbing)。
标签保护有旋转,变色等视觉上的变换,标签扰动主要用于分类。
CrossNorm 也是一种数据增强的方法,并且很容易应用到各个领域和任务上,其目标是提高分布偏移下的泛化性和鲁棒性,这和许多传统的数据增强方法有些不同。
Preliminary
CrossNorm 和 SelfNorm 都是基于 Instance Normalization 的。
Instance Normalization
假设有 feature map 𝒜 ∈ ℝH × W, Instance Normalization 对 feature map 做 normalization 并做一个仿射变换:
$$ \gamma \dfrac{\mathcal{A} - \mu_{\mathcal{A}}}{\sigma_{\mathcal{A}}} + \beta $$
μ𝒜 和 σ𝒜 能解码风格信息。
风格定义
在这篇文章中,风格是指与感兴趣的语义内容相关的一些信息。SelfNorm 起作用的原因可能是注意力可能有助于强调基本风格并抑制琐碎的风格。
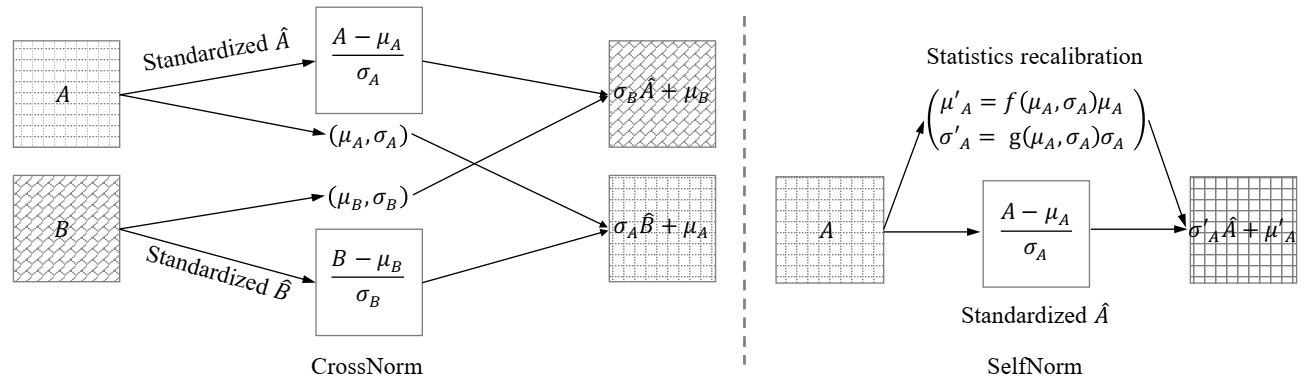
CrossNorm
CrossNorm 将 𝒜 通道的 μ𝒜 和 σ𝒜 和 ℬ 通道的 μℬ 和 σℬ 进行交换
$$ \sigma_{\mathcal{B}} \frac{\mathcal{A}-\mu_{\mathcal{A}}}{\sigma_{\mathcal{A}}}+\mu_{\mathcal{B}} \quad \sigma_{\mathcal{A}} \frac{\mathcal{B}-\mu_{\mathcal{B}}}{\sigma_{\mathcal{B}}}+\mu_{\mathcal{A}} $$
CrossNorm 包括三种变换:
- 1-instance mode: 对于 CNNs, 对 𝒳 ∈ ℝC × H × W, CrossNorm 交换通道 C 的统计量: {(𝒜, ℬ) ∈ (𝒳i, :,:, 𝒳j, :,:) ∣ i ≠ j, 0 < i, j < C}.
- 2-instance mode: 给出两个 Instance 𝒳, 𝒴 ∈ ℝC × H × W, CrossNorm 交换其对应通道的统计量使 𝒜 和 ℬ 变为: {(𝒜, ℬ) ∈ (𝒳i, :,:, 𝒴i, :,:) ∣ 0 < i < C}
- Crop: 局部交换,{(𝒜, ℬ) ∈ (crop (𝒜), crop (ℬ)) ∣ rcrop ≥ t},其面积比例不低于 t.
SelfNorm
SelfNorm 将 IN 中的 β 和 γ 替换为 μ𝒜′ = f(μ𝒜, σ𝒜)μ𝒜 和 σ𝒜′ = g(μ𝒜, σ𝒜)σ𝒜, 如上图所示, 其中的 f 和 $g $ 表示注意力函数。调整后的 Feature Map 为:
$$ \sigma_{\mathcal{A}}^{\prime} \frac{\mathcal{A}-\mu_{\mathcal{A}}}{\sigma_{\mathcal{A}}}+\mu_{\mathcal{A}}^{\prime} $$
在具体的实现中,使用了两个全连接层来实现 f 和 g 两个注意力函数。
与 SE 模块的区别
SE 模块[4]是 SENet 中提出的一种基于通道注意力的模块。
- SE 模块依赖通道间相关性,而 SelfNorm 单独处理每个通道
- SE 模块针对的是通道特征而 SelfNorm 处理的是通道的统计量
- SE 模块的复杂度为 O(C2), SelfNorm 的复杂度为 O(C), 其中 C 是通道数量
Detail

CrossNorm 只在训练时使用,SelfNorm 在训练和测试时都使用。SelfNorm 是可学习模块,需要经过训练才能工作。CrossNorm 可以增强 SelfNorm 的性能,因为 CrossNorm 可以对风格进行增强来使得 SelfNorm 对更多风格起作用。两种方法协同工作提高了泛化能力鲁棒性。
模块设计:CrossNorm 和 SelfNorm 都能灵活使用,但插入到模型中什么位置有待研究:后面进行了消融实验,附录中展示了这方面的具体研究。例如,在 Resnet 中插入到残差块中。
Experiment
文中实验部分展示了 6 项实验结果,文中的排版是先逐一介绍用到的数据集,再详细说明每个实验的一些实验参数设置及实验结论。
总的参数设置:文中指出模型参数设置与Augmix开源仓库的超参数是一致的。所有模型结构中都是CN放在SN前面,论文附录中探究了CNSN放在位置的影响,实验结果展示中CNSN放在残差块后面。实验中激活CrossNorm,CrossNorm使用2-instance与Crop结合的模式,threshold设为0.1。(后续其他类型)
分类任务
数据集:CIFAR-10, CIFAR-100, ImageNet, CIFAR-10-C, CIFAR-100-C, ImageNet-C
数据集简介:CIFAR的两个数据集是分类中常用数据集,CIFAR-10 有 60000 张图片,10个分类,每类6000张长宽均为32的三通道彩色图像,其中50000张为训练集,10000张为测试集。CIFAR-100与CIFAR-10类似,但有100分类,每个分类600张图片。ImageNet包含14197122张图片,是一个超大的分类数据集。而后续的带有 -C 的数据集是在原数据集的基础上添加了一些干扰,用于验证模型的泛化性和鲁棒性,例如下图所示:

实验结果:
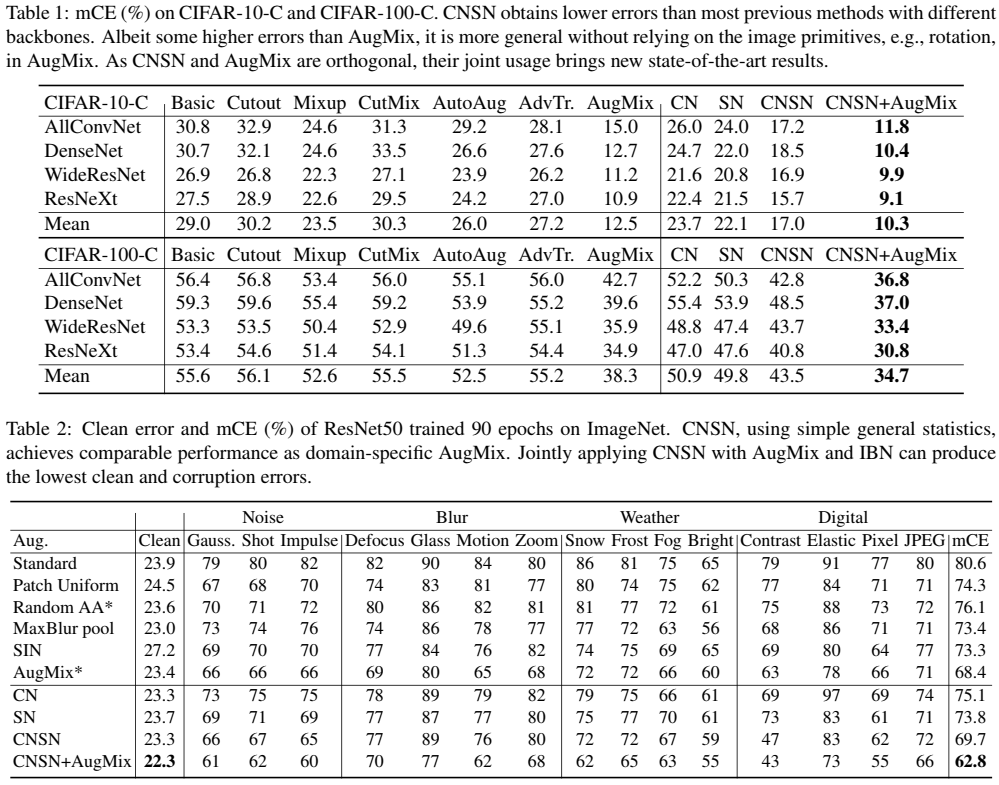
第一个表格是CIFAR-10,CIFAR-100的实验结果,第二个表格是ImageNet的实验结果, 实验中设置了 Basic 作为基线,六种数据增强的方法对比,CrossNorm, SelfNorm,单独的效果,结合的效果,以及与 Augmix结合的效果。
实验结论:CNSN与Augmix结合后的效果达到了 SOTA,鲁棒性和泛化性有显著提高,并且对原图的性能也有所提高。
半监督分类
数据集:CIFAR-10
参数设置:模型设置与SOTA的FixMatch[8] 设置相同。使用28-2 Wide-Resnet训练了1024 epochs, 使用 SGD 优化,动量0.9,学习率0.03,权重衰减5e-4,生成伪标签比例为0.95,未标记数据的权重损失为1,使用随机数种子为 1 的随机数生成器分别随机采集250,4000个标签(检查过了原文确实是 4000,但表格中是 1000?)
实验结果:
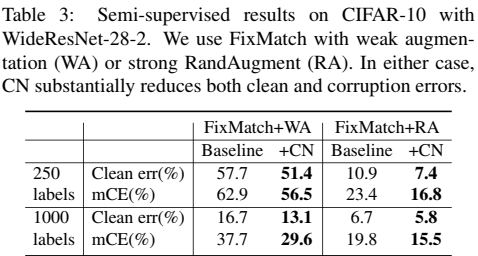
实验结论:CN降低了分类错误率
合成数据集到真实数据集的泛化
数据集:GTA5,Cityscapes
数据集介绍:GTA5是合成的城市场景数据集,有12403训练数据,6382验证数据,6181测试数据,Cityscapes是真实的城市场景数据集,有超过2975500训练数据和1525测试数据。
参数设置:以Resnet50 为 backbone的FAN,80 epochs,batch size为16,使用ImageNet的预训练权重初始化,在源域和目标域都进行测试 实验结果:
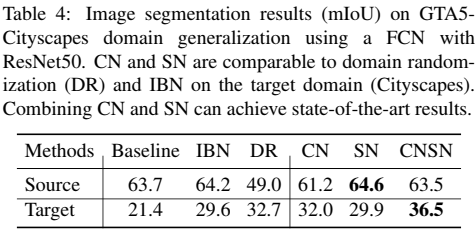
实验结果:CNSN都能有效提高在目标域的准确率。CN能让网络学习到更多域不变的特征,SN能让网络更加关注跨域的通用特征,二者结合达到SOTA的结果。
NLP的跨数据集泛化性
数据集:IMDb, SST-2
数据集介绍:IMDb是一个二元情感分析数据集,由来自互联网电影数据库的 50,000 条评论组成,有25000条正面评论和25000条负面评论。SST-2也是电影评论,包含 9613条训练数据和1821条测试数据。
参数设置:使用GloVe 词嵌入和卷积神经网络。使用Adam优化器训练20 epochs。
实验结果:
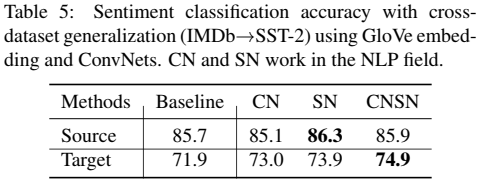
实验结论:实验结果表明CNSN在NLP领域也是有用的而不仅仅局限于计算机视觉,尽管在NLP方面确实像图像一般的直观解释,均值和方差在NLP数据中也能通过减少分布偏移提高泛化性能。
域适应
数据集:Office-31
数据集介绍:Office-31有三个域31个分类4652张图片。三个域分别为:Amazon (A) ( amazon.com images), Webcam (W) ( web camera images) 和 DSLR (D) (digital SLR camera images)
参数设置:使用ResNet 50, Batch size 32, Adam 优化器,学习率1e-5,权重衰减2.5e-5,训练 100 epochs
实验结果:
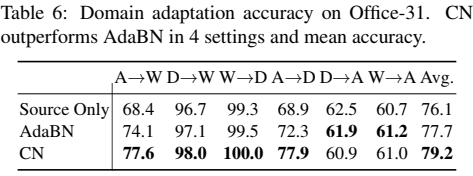
实验结论:可见D->A 和 W->A 略差与 AdaBN,论文解释这可能是因为D和W域的图片都比A少得多的原因。
可视化

Conclusion
这篇文章解释了如何针对分布偏移使用 Normalization 提高泛化性能,并以此提出了 CrossNorm 和 SelfNorm 这两种简单有效互补的 Normalization 的方法。他们的广泛应用说明了一种适用于视觉和语言等多个领域的通用方法。由于 CrossNorm 和 SelfNorm 非常简单,因此还有很大的改进空间,一个可能的方向是探索更好的风格表示形式,因为这两种方法中使用的平均值和方差并不是编码各种风格的最佳方法。
Others
分类任务论文复现
| CIFAR-10/ResNeXt | 论文结果 | 复现结果 | gaussian_noise | shot_noise | impulse_noise | defocus_blur | glass_blur | motion_blur | zoom_blur | snow | frost | fog | brightness | contrast | elastic_transform | pixelate | jpeg_compression |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CN | 22.4 | 22.198 | 49.670 | 38.062 | 41.364 | 11.866 | 42.872 | 16.354 | 13.992 | 14.136 | 17.364 | 9.160 | 5.850 | 15.582 | 14.104 | 22.148 | 20.444 |
| SN | 21.5 | 22.231 | 47.288 | 36.036 | 41.730 | 13.860 | 33.526 | 18.486 | 17.746 | 13.454 | 16.322 | 10.868 | 5.612 | 19.632 | 14.798 | 24.338 | 19.774 |
| CNSN | 15.7 | 16.240 | 36.868 | 29.218 | 28.374 | 7.922 | 32.194 | 10.224 | 10.670 | 10.456 | 11.320 | 7.638 | 4.900 | 8.348 | 11.540 | 16.116 | 17.810 |
| CNSN+AugMix | 9.1 | 9.816 | 23.406 | 16.838 | 10.686 | 5.080 | 16.332 | 6.272 | 6.132 | 7.720 | 7.498 | 7.070 | 4.662 | 5.696 | 8.238 | 10.580 | 11.024 |
| CIFAR-10/WideResnet | 论文结果 | 复现结果 | gaussian_noise | shot_noise | impulse_noise | defocus_blur | glass_blur | motion_blur | zoom_blur | snow | frost | fog | brightness | contrast | elastic_transform | pixelate | jpeg_compression |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CN | 21.6 | 21.408 | 44.486 | 34.366 | 36.794 | 11.802 | 41.776 | 15.260 | 14.742 | 16.056 | 18.702 | 9.564 | 6.758 | 15.392 | 14.566 | 19.614 | 21.244 |
| SN | 20.8 | 22.239 | 42.722 | 32.722 | 38.284 | 14.006 | 40.336 | 17.296 | 20.452 | 15.174 | 17.536 | 10.692 | 6.420 | 17.052 | 15.180 | 25.820 | 19.900 |
| CNSN | 16.9 | 17.705 | 34.008 | 27.156 | 29.102 | 10.712 | 32.454 | 14.176 | 13.944 | 13.344 | 13.798 | 9.446 | 6.342 | 10.424 | 13.812 | 17.488 | 19.364 |
| CNSN+AugMix | 9.9 | 10.334 | 16.078 | 12.750 | 13.368 | 6.820 | 16.680 | 7.730 | 8.320 | 9.974 | 9.400 | 8.594 | 6.304 | 7.788 | 9.974 | 9.284 | 11.948 |
| CIFAR-100/ResNeXt | 论文结果 | 复现结果 | gaussian_noise | shot_noise | impulse_noise | defocus_blur | glass_blur | motion_blur | zoom_blur | snow | frost | fog | brightness | contrast | elastic_transform | pixelate | jpeg_compression |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CN | 47.0 | 47.260 | 78.618 | 69.512 | 69.922 | 33.790 | 75.954 | 39.732 | 38.330 | 40.506 | 44.618 | 30.610 | 23.782 | 37.952 | 35.586 | 41.180 | 48.812 |
| SN | 47.6 | 47.997 | 79.672 | 71.686 | 73.314 | 33.044 | 75.340 | 39.538 | 38.660 | 39.186 | 44.788 | 32.080 | 23.086 | 39.244 | 35.680 | 45.662 | 48.978 |
| CNSN | 40.8 | 43.801 | 73.700 | 65.756 | 59.370 | 31.342 | 67.804 | 35.724 | 35.908 | 36.300 | 41.322 | 31.842 | 23.684 | 35.180 | 34.150 | 37.200 | 47.728 |
| CNSN+AugMix | 30.8 | 30.951 | 45.748 | 38.604 | 31.990 | 23.392 | 43.006 | 25.914 | 25.154 | 29.000 | 30.484 | 30.074 | 23.406 | 26.362 | 28.220 | 28.964 | 33.952 |
| CIFAR-100/WideResnet | 论文结果 | 复现结果 | gaussian_noise | shot_noise | impulse_noise | defocus_blur | glass_blur | motion_blur | zoom_blur | snow | frost | fog | brightness | contrast | elastic_transform | pixelate | jpeg_compression |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CN | 48.8 | 48.746 | 73.252 | 65.216 | 70.956 | 36.542 | 72.472 | 42.398 | 40.956 | 43.528 | 45.922 | 35.672 | 28.604 | 41.594 | 39.472 | 44.764 | 49.848 |
| SN | 47.4 | 48.566 | 69.794 | 62.508 | 65.500 | 38.666 | 67.574 | 44.872 | 44.434 | 43.138 | 45.806 | 39.208 | 29.574 | 46.144 | 39.172 | 45.652 | 46.450 |
| CNSN | 43.7 | 43.824 | 66.338 | 58.518 | 62.782 | 33.332 | 63.888 | 37.150 | 37.336 | 38.766 | 40.762 | 33.342 | 27.216 | 35.388 | 36.128 | 41.220 | 45.194 |
| CNSN+AugMix | 33.4 | 34.111 | 47.370 | 41.012 | 37.932 | 26.336 | 45.620 | 28.840 | 28.586 | 32.798 | 35.010 | 31.750 | 26.884 | 31.330 | 31.778 | 30.380 | 36.034 |
其中黄色标注的行是标题,标题中第一栏标明了使用的数据集和模型,蓝色栏是论文中给出的实验数据,绿色栏是论文复现得到的结果,(因为原本的图片太模糊了,所以转为了
markdown
内置表格样式),后面15列是论文结果复现中CIFAR-10-C和CIFAR-100-C下各个子数据集单独的测试结果,复现结果是对这15个子集取平均值得到的。
可见在结果复现中我们得到了与论文展示结果十分接近的结果,证明了论文提出的方法的有效性。
通过对代码分析和结果复现,进一步加深了对论文方法的理解,也对论文提出方法的效果有更进一步的了解
一些细节:
Step 1. 将作者提供的开源代码 git 到本地或服务器并打开对应文件夹
1 | git https://github.com/amazon-research/crossnorm-selfnorm.git |
Step 2. 按照作者给出的要求配置环境(我的服务器上已有配置好的环境,所以这一步跳过了)
1 | conda create --name cnsn python=3.7 |
Step 3. 下载所需测试数据集,解压到指定位置
1 | mkdir -p ./data |
Step 4. 修改 cifar10-scripts 中的 sh 脚本文件参数,运行得到实验结果
这里的修改参数指存放数据集的路径,使用的GPU编号,以及对显存占用过大的训练减小Batchsize等
受设备限制,这里只复现 CIFAR-10 和 CIFAR-100 的结果,ImageNet 不进行复现
源码解析
在开源代码中很容易找到 CNSN 的核心实现源码 (cnsn.py),我们对其进行分步解析
导入库,这个没什么好说的
1 | import torch |
第一个函数,主要功能是计算给出 tensor 的通道均值和方差,输入 tensor 维度为 (B, C, H, W), 分别表示批量大小,通道数和 Feature map 的长宽。注意到计算是为了防止除零错,给方差加上了一个小常数 eps,默认值为 1e-5,返回值的维度均为 (B, C, 1, 1).
1 | def calc_ins_mean_std(x, eps=1e-5): |
第二个函数,给出原风格的 feature map 为 content_feat,目标 feature map 为 style_feat,按照论文中 CrossNorm 的方法将 style_feat 的风格迁移到 content_feat 上。
1 | def instance_norm_mix(content_feat, style_feat): |
第三个函数,随机对给定的张量裁剪出一小块范围,若裁剪的大小未达到指定的比例 bbx_thres,则重新裁剪,直到达到指定的要求,最后返回裁剪区域的两个坐标.
1 | def cn_rand_bbox(size, beta, bbx_thres): |
第四个函数,是 CrossNorm 的主要实现,具体来说,是第二种和第三种模式的混合实现(实际上第一种模式也可以看作这种实现的一个特例),依次可以实现论文中提到的 CrossNorm 的三种模式(即单张图片通道交换,不同图片对应通道交换,局部交换-包含风格和语义两部分),其首先使用了 torch.randperm 函数获得了打乱顺序的 feature map,随后看参数是否需要局部裁剪,若需要风格局部裁剪则调用上一个函数获取裁剪的坐标进行裁剪,chan 控制是否进行单张图片的通道交换(即第一种模式),随后是语义的局部裁剪,这里主要通过 mask 矩阵实现。随后是 lam 控制的是否进行类似权重衰减的迭代操作,最后返回结果。
1 | def cn_op_2ins_space_chan(x, crop='neither', beta=1, bbx_thres=0.1, lam=None, chan=False): |
第一个类定义是 CrossNorm层 的实现:使用functools.partial定义了 CrossNorm 实现的具体操作函数(该函数可以理解为一个装饰器,对传入函数设定默认值,返回包装后的函数,这里传入的是上一个定义的函数,即 CrossNorm 的具体实现),另一个参数是控制 CrossNorm 层是否其作用,forward是前向传播,即在模型处于训练且 CrossNorm 激活的条件下才进行 CrossNorm 操作,并在操作后取消激活。
1 | class CrossNorm(nn.Module): |
第二个类定义了 SelfNorm 层,初始化中定义了两个全连接层(卷积Conv1d实现)和两个BatchNorm层,forward 前向传播函数展示了 SelfNorm 如何作用:首先计算输入 feature map 的均值和方差,将其降维后连接得到了 (B, C, 2) 的 statistics,随后分别先后输入到1维卷积(这里可以看出为什么说是卷积实现的全连接,因为是在每个通道上计算一个 2 × 1 的全连接,外在表现是卷积操作)和BatchNorm层实现的简单注意力变化层,得到新的均值和方差,对输入做归一化和用新的均值和方差进行逆归一化操作,这里将两边合为一步并进行了计算的化简,最后将得到的结果进行前向传递返回。
1 | class SelfNorm(nn.Module): |
第三个类定义将 CrossNorm 和 SelfNorm 打包到一起作为一个类,没有其他额外需要注意的地方。
1 | class CNSN(nn.Module): |
不足之处
- SelfNorm 的注意力十分简单,可以考虑更加有效的注意力机制实现方式,例如文中提到的SE模块。
- CrossNorm 作为一种增强方法,可以考虑同时作为图片数据增强方法加入到数据预处理中。
- 论文中CrossNorm 和 SelfNorm 都是放在一起的,若将两个模块分开放在模型的不同位置,例如 CrossNorm 放在卷积前,SelfNorm 放在残差前是否会有更好的表现呢?
- CrossNorm 和 SelfNorm 只能增强已有分类的未知风格,而没有针对未知类别进行增强。可以考虑结合无监督和半监督的方法来增强对未知类别的分类能力。
探索性研究
- 实验结果展示 CrossNorm 和 SelfNorm 结合 Augmix 会有极大的增益,那么能否将一些已有的方法结合达到类似的效果呢?例如MixtureNorm[5] 和 SwitchableNorm[6] 这样的方法。
- 将注意力与Normalization结合的方法也是值得探究的点。AttentiveNorm[7] 是一个有意思的例子。
- 在对抗样本的攻防方面 CrossNorm 和 SelfNorm 简单的测试展现了不错的效果,可以考虑如何在对抗中提高攻击和防御。
- 文中只使用了简单的风格变换,可以考虑使用对抗生成网络来生成更精细的风格变换和迁移,以进一步提高网络的鲁棒性和泛化性。
- 能否和无监督或半监督的聚类相关算法结合改进提高网络的性能呢?
- 在文中的变换只使用了一阶统计量,是否可以结合二阶统计量或更高阶的统计量进行优化改进呢?或者说更高阶的统计量是否也表达了一些特点的语义信息,通过对这些语义信息进行迁移和扩增是否对网络的性能,鲁棒性和泛化性有益呢?
References
如果对你有帮助的话,请给我点个赞吧~
欢迎前往 我的博客 查看更多笔记- 1.Robert Geirhos, Patricia Rubisch, Claudio Michaelis, Matthias Bethge, Felix A Wichmann, and Wieland Brendel. Imagenet-trained cnns are biased towards texture; increasing shape bias improves accuracy and robustness. In Proceedings of the International Conference on Learning Representations, 2019. ↩︎
- 2.Xingang Pan, Ping Luo, Jianping Shi, and Xiaoou Tang. Two at once: Enhancing learning and generalization capacities via ibn-net. In Proceedings of the European Conference on Computer Vision (ECCV), pages 464–479, 2018. ↩︎
- 3.Xiangyu Yue, Yang Zhang, Sicheng Zhao, Alberto Sangiovanni-Vincentelli, Kurt Keutzer, and Boqing Gong. Domain randomization and pyramid consistency: Simulation-to-real generalization without accessing target domain data. In Proceedings of the IEEE International Conference on Computer Vision, pages 2100-2110, 2019. ↩︎
- 4.Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7132–7141, 2018. ↩︎
- 5.Kalayeh, M.M., Shah, M.: Training faster by separating modes of variation in batch-normalized models. IEEE Trans. Pattern Anal. Mach. Intell. 42, 1-1 (2019). ↩︎
- 6.Luo, P., Ren, J., Peng, Z.: Differentiable learning-to-normalize via switchable normalization. CoRR abs/1806.10779 (2018) ↩︎
- 7.X. Li, W. Sun, and T. Wu, “Attentive Normalization,” in Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 2020, vol. 12362 LNCS, pp. 70–87. ↩︎
- 8.Kihyuk Sohn, David Berthelot, Chun-Liang Li, Zizhao Zhang, Nicholas Carlini, Ekin D Cubuk, Alex Kurakin, Han Zhang, and Colin Raffel. Fixmatch: Simplifying semisupervised learning with consistency and confidence. arXiv preprint arXiv:2001.07685, 2020. ↩︎