摘要
蒙特卡洛方法是一种通过随机重复采样获取存在确切数值解的求解方法,马尔可夫链是一类具有无后效性的随机过程,在较高维度的随机变量采样过程中,蒙特卡洛方法和其他传统的方法都遇到了维度灾难的问题,而马尔可夫链蒙特卡洛方法将蒙特卡洛方法和马尔可夫链的性质进行了结合,可以有效的避免维度灾难的问题,是高维度采样中一种有效的解决方案。本文简单介绍了蒙特卡洛方法和马尔可夫链的基本定义,随后以经典的 Metropolis–Hastings 方法为例详细介绍了马尔可夫链蒙特卡洛方法的思路及其形式推导,并给出了简单的例子和实验验证了算法的有效性。
蒙特卡洛方法
蒙特卡洛方法(Monte Carlo method/experiments) 是一种通过随机重复采样获取存在确切数值解的求解方法。蒙特卡洛方法通常可以用在如下三类问题的求解:
- 数值优化问题
- 数值积分问题
- 概率分布的一般化采样
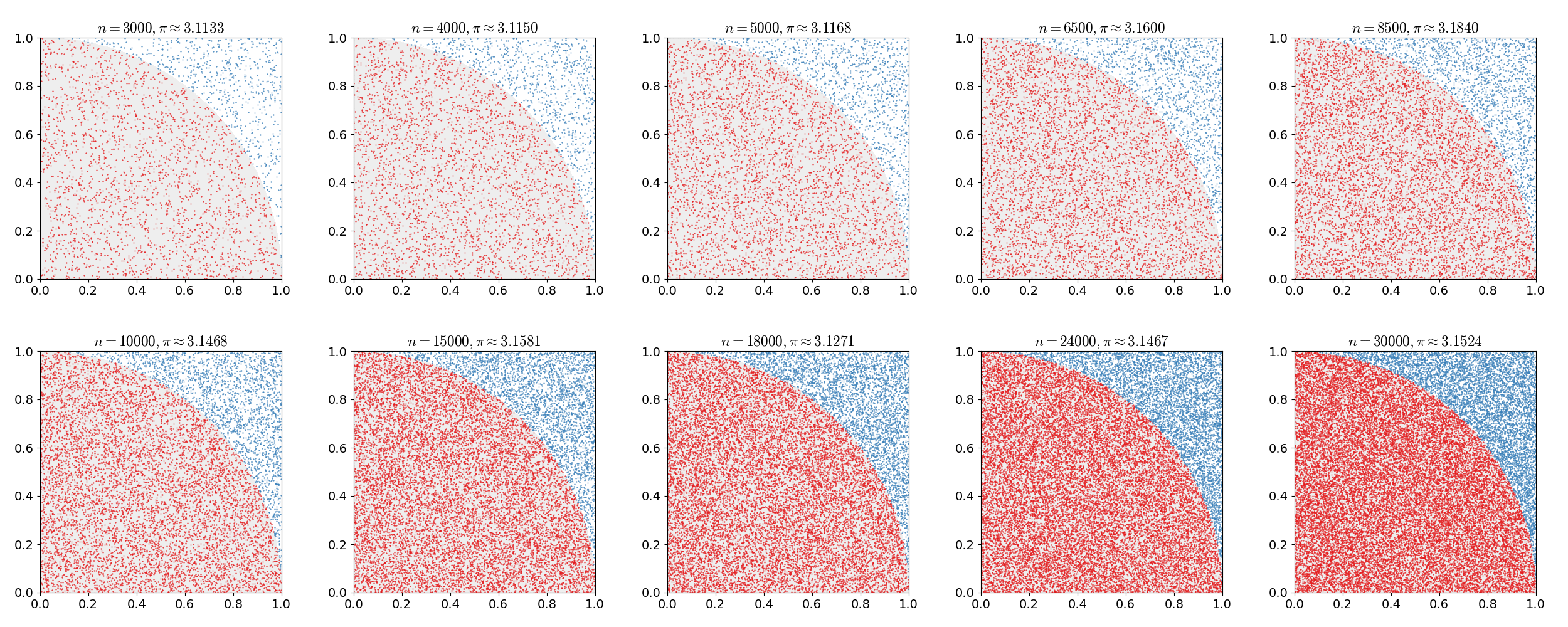
例如对圆周率的估计就可以采用蒙特卡洛方法进行模拟,考虑单位长度的正方形中绘制一个 $\dfrac{1}{4}$ 圆,其面积为 $\dfrac{\pi}{4}$, 根据几何概型,在正方形中随机投点的情况下,点落入圆中的概率为 $\dfrac{\text{圆的面积} }{\text{正方形的面积} }$,即 $\dfrac{\pi / 4}{1}$, 由此我们可以推算出圆周率的估计值为 π = 4p, 其中 p 表示在正方形中随机投点落在圆内的概率,根据蒙特卡洛模拟可以获得其近似值,如下图所示,模拟次数越多,越接近真实值。
同样也可以使用数值积分的方法计算,即
$$ \int_0^1 \sqrt{1 - x^2} dx = \dfrac{\pi}{4} $$
模拟计算代码如下:
1 | def f(x): |
输出结果为:
1 | 蒙特卡洛方法模拟 100 次的结果为 3.1289951863 |
马尔可夫链
简介
马尔可夫链(或马尔可夫过程, Markov chainprocess)是描述一系列可能事件的随机模型,其中每个事件的概率仅取决于前一个事件中获得的状态。
转移:马尔可夫状态改变的过程称为状态的转移,与各种状态变化相关的概率称为转移概率。马尔可夫过程的特征在于状态空间、描述特定转移概率的转移矩阵以及整个状态空间的初始状态(或初始分布)
示例
举个例子:一种只吃奶酪、葡萄或生菜的高度理论动物的饮食习惯,其饮食习惯符合以下规则:
- 它每天只吃一次。
- 如果它今天吃奶酪,明天它会以相同的概率吃生菜或葡萄。
- 如果它今天吃葡萄,明天它将以 1/10 的概率吃葡萄,以 4/10 的概率吃奶酪,以 5/10 的概率吃生菜。
- 如果它今天吃生菜,明天它将以 4/10 的概率吃葡萄或以 6/10 的概率吃奶酪。明天它不会再吃生菜了。
可以写出其转移概率矩阵为
$$ \begin{bmatrix} 0 & 0.5 & 0.5 \\ 0.4 & 0.1 & 0.5 \\ 0.6 & 0.4 & 0 \end{bmatrix} $$
考虑第一天吃不同的食物,通过计算发现,一段时间后吃三种食物的都趋于 $\dfrac{1}{3}$。
1 | import numpy as np |
两次输出结果如下:
1 | 第一天吃 奶酪, 10 天后吃 奶酪, 葡萄, 生菜 的概率分别为 0.33398, 0.33301, 0.33301 |
$\left(\dfrac{1}{3}, \dfrac{1}{3}, \dfrac{1}{3}\right)$ 是该例子下的一个稳态分布。
我们可以使用蒙特卡洛的方法来验证一下上述结论的正确性
1 | import random |
模拟结果为:
1 | 第一天吃 奶酪, 100 天后吃 奶酪, 葡萄, 生菜 的概率分别为 0.33132, 0.33420, 0.33448 |
显然模拟的结果与计算结果基本一致,说明了无论第一天吃什么食物,在一定次数的转移(过去一定时间)后吃三种食物的事件的是等概率事件。
数学定义
马尔可夫链的数学定义为:
Pr(Xn + 1 = x ∣ X1 = x1, X2 = x2, …, Xn = xn) = Pr(Xn + 1 = x ∣ Xn = xn)
即转移到下一个状态的概率仅取决于当前状态而不取决于之前的状态。
马尔可夫链蒙特卡洛方法
马尔可夫链蒙特卡洛(Markov chain Monte Carlo, MCMC) 是一种通用的从给定概率分布中采样的随机采样方法,即使是对于一些其他方法很难采样的概率分布,MCMC 都能使用。MCMC 方法构造具有马尔可夫性质的随机变量序列,其概率分布极限为目标分布。因为符合要求的序列构造比较容易,而目标分布范围很广,因此 MCMC 得到了广泛的应用。MCMC 通常用于从多维分布中采样,尤其是在维数很高的情况下,许多采样算法都有“维度灾难”的问题,此时 MCMC 是一种较好的解决方案。
MCMC 有两种比较经典的算法:Metropolis–Hastings (M-H) 算法和 Gibbs sampling. 这里主要介绍 M-H 算法。
Metropolis–Hastings
基本思想
Metropolis-Hastings 算法可以从任何任意具有概率密度 P(x) 的概率分布中抽取样本, 前提是我们知道一个与概率密度 P 成正比的函数 f(x) 并且 f(x) 的值可以计算。Metropolis-Hastings 算法只 f(x) 与概率密度成正比,而不是完全等于它,这使得 Metropolis-Hastings 算法特别有用,因为在实践中计算归一化因子通常非常困难。
Metropolis-Hastings 算法的工作原理是生成一系列样本值,随着生成的样本值越来越多,值的分布更接近于所需的分布。这些样本值是迭代生成的,下一个样本的分布仅取决于当前样本值(从而使样本序列成为马尔可夫链)。具体来说,在每次迭代中,算法都会根据当前样本值选择下一个样本值的候选者。然后,以某种概率,候选被接受(在这种情况下,候选值在下一次迭代中使用)或被拒绝(在这种情况下,候选值被丢弃,当前值在下一次迭代中被重用)
形式推导
Metropolis-Hastings 算法根据期望分布 P(x) 生成状态集合. 在具体实现中使用了马尔可夫链,即在生成过程中渐近地达到一个唯一的平稳分布 π(x) 满足 π(x) = P(x).
马尔可夫链由其转移概率 P(x′ ∣ x) 唯一确定,表示由任意给定的状态 x 转移到任意其他给定的状态 x′, 当满足下面两个条件的时候马尔可夫链具有唯一的平稳分布:
- 存在平稳分布 π(x), 一个充分不必要条件是细微平衡(detailed balance), 即要求每次的转移 x → x′ 都是可逆的:给定一对状态 x, x′, 满足 π(x)P(x′ ∣ x) = π(x′)P(x ∣ x′), 即 x → x′ 与 x′ → x 的转移概率要相等
- 平稳分布唯一
平稳分布的唯一性由马尔可夫链的遍历性保证,这要求
- 马尔可夫链的所有状态都是非周期的,即不会再固定的间隔返回同一个状态
- 马尔可夫链的所有状态都是正循环的,即能在有限步返回同一个状态
M-H 算法需要通过构建转移概率设计出满足上面两个条件的马尔可夫链,使其平稳分布 π(x) 满足 P(x), 我们先考虑细微平衡: P(x)P(x′ ∣ x) = P(x′)P(x ∣ x′) 整理一下 $$ \dfrac{P(x' \mid x)}{P(x \mid x')} = \dfrac{P(x')}{P(x)} $$
M-H 算法将 P 分成两个子步骤:提议和接受-拒绝。
- 提议分布 g(x′ ∣ x) 是在给定 x 的情况下提议状态 x′ 的条件概率
- 接受分布 A(x′, x) 是接受提议状态 x′ 的概率
所以有: P(x′ ∣ x) = g(x′ ∣ x)A(x′, x) 代入前面的方程,得到: $$ \dfrac{g(x'\mid x)A(x', x)}{g(x\mid x')A(x, x')} = \dfrac{P(x')}{P(x)} $$ 即 $$ \dfrac{A(x', x)}{A(x, x')} = \dfrac{P(x')}{P(x)} \dfrac{g(x\mid x')}{g(x'\mid x)} $$
下一步是选择满足上述条件的接受率。一种常见的选择是 Metropolis 选择: $$ A(x', x) = \min \left(1, \dfrac{P(x')}{P(x)} \dfrac{g(x\mid x')}{g(x'\mid x)}\right) $$
对 Metropolis 接受率 A,有 A(x′, x) = 1 或 A(x, x′) = 1, 满足条件
基本流程
M-H 算法基于两个阶段:
- 从提议分布(也叫候选生成分布)生成候选随机值
- 根据 Metropolis 规则接受或拒绝候选值
给定当前状态值 x, Metropolis 规则根据如下概率接受候选值 w
$$ {\rho}({x},{w}) = \min\left\{\frac{ {p}({w}){q}({x}\,{\vert}\,{w})}{ {p}({x}){q}({w}\,{\vert}\,{x})},{1}\right\},\quad{x},{w}\,\in\,{\cal{X} }, \tag{1} $$
其中 q(⋅ | x) 是提议密度函数。对每个 x, 由 q(⋅ | x) 确定的概率分布被假定为连续分布(但不是一般要求)。
为了确保这个接受概率是明确定义的,当 p(x)q(w | x) = 0 时令 ρ(x, w) = 1.
Metropolis-Hastings 算法流程为
- (初始化)为 X0 选择初始状态 x0. 设置 k = 0.
- 给定 Xk, 根据提议密度 q(⋅ | Xk) 生成候选点 W.
- 对给定 W 令 $$ {\boldsymbol{X} }_{k + 1} = \begin{cases} \begin{array}{ll}{\boldsymbol{W} },&{\text{概率为 } }{\rho}({\boldsymbol{X} }_{k},{\boldsymbol{W} }),\\ {\boldsymbol{X} }_{k},&{\text{概率为 } }{1} - {\rho}({\boldsymbol{X} }_{k},{\boldsymbol{W} }). \end{array} \end{cases} $$ 更新计数器 k → k + 1
- 重复 2,3 知道得到合法的终值 Xn
一个例子
举个例子,给定目标概率密度函数为: $$ \begin{equation*} {p}({x_1},{x_2}) = \begin{cases} \begin{array}{ll} {\beta}{e}^{-{x_1}{x_2} }&{\text{if } }{0}\,{<}\,{x}_{j}\,{<}\,{B},{j} = {1},{2},\\ {0}&{\text{other wise,} } \end{array} \end{cases} \tag{2} \end{equation*} $$ 其中 β 是正则化常数,提议密度设为二维均匀分布: $$ {q}({\boldsymbol{y} }) = \frac{1}{B^2}{\boldsymbol{I} }_{\cal{X} }({\boldsymbol{y} }),\quad{\boldsymbol{y} } = ({\boldsymbol{y} }_{1},{\boldsymbol{y} }_{2})\,\in\,{\cal{X} }. \tag{3} $$ 则 Metropolis 规则为 $$ \begin{equation*} {\rho}({\boldsymbol{x} },{\boldsymbol{y} }) = \begin{cases} \begin{array}{ll} {1},&{\text{if } }{y_1}{y_2}\,{<}\,{x_1}{x_2},\\ {e}^{-({y_1}{y_2} - {x_1}{x_2})},&{\text{if } }{y_1}{y_2}\,≥\,{x_1}{x_2}, \end{array} \end{cases} \tag{4} \end{equation*} $$
马尔可夫链从一个状态值转移到另一个状态值的概率由 M-H 算法的步骤 2 和 3 确定。因此,给定 Xk = x 转移到 Xk + 1 = y 的概率仅取决于 Metropolis 接受概率 ρ(⋅, ⋅) 和提案密度 q(⋅ | ⋅),两者都不依赖于索引 k。由此可见,从一个状态值转移到另一个状态值的条件概率密度与 k 无关。这种由 K(y | y) 表示的条件概率密度称为转移核,类似于离散马尔可夫链中的转移矩阵 P。当在 ${\cal{X} }$ 的子集上积分时,转移核产生马尔可夫链的一步转移概率,这是给定 Xk 转移到 Xk + 1 的条件概率。具体来说,给定点 ${x}\,\in\,{\cal{X} }$,集合 ${A}\,\subseteq\,{\cal{X} }$ 的转移概率由积分 ∫AK(y | x)dy 确定。这个条件概率记为 P(Xk + 1 ∈ A | Xk = x)。对于每个 ${\boldsymbol{x} }\,\in\,{\cal{X} }$, P(Xk + 1 ∈ A | Xk = x) = ∫AK(y | x)dy, k = 0, 1, 2, ….
k-步转移概率密度函数 K(k)(⋅ | ⋅) 可以由 CK 方程 (Chapman–Kolmogorov) 计算得到: K(k + 1)(y | x) = ∫K(k)(y | v)K(v | x)dv = ∫K(y | v)K(k)(v | x)dv,
当 k = 1 时 K(1)(⋅ | ⋅) 是转移核本身。由此可以计算出 k-步转移概率为 P(Xk ∈ A | X0 = x) = ∫AK(k)(y | x)dy.
提议密度的选择
用于生成候选值的提议密度 q(⋅ | x) 可以非常灵活选择,但也有些要求。为了使 M-H 算法收敛到 (28) 或 (29) , 要求提议密度能够生成从 ${\cal{X} }$ 的任意状态值开始在有限步内能以非零概率到达 S 任意子集的随机样本。除此之外,提议密度还必须能够生成不可约的 M-H 马尔可夫链 {Xk}。
提议密度的必要条件是 ∃ η > 0, 对 $\forall \, {\boldsymbol{x} },{\boldsymbol{y} }\,\in\,{\cal{X} }$ 有 q(y | x) > 0 且 ‖y − x‖ < η。
另一个需要注意的方面是提议密度的接受率,接受率定义为马尔可夫链在平稳状态下接受提议转移的概率,即 ∫ρ(x, y)q(y | x)p(x)dxdy.
最佳接受率定义为最小化 ∫f(x)dx 的估计 ∑K = 1nf(Xk)/n 的渐进方差的比例。[6] 中指出,假设来自目标密度的随机向量具有相同的独立分布,在高维状态空间中,对于具有对角协方差矩阵的高斯提议密度,最佳接受率约为 23.4%。
转移核
对于转移核 K(⋅ | ⋅), 给定 x 和 w, 输出 y 满足 $$ \begin{equation*}{\boldsymbol{y} } = \begin{cases}\begin{array}{l}{\boldsymbol{w} }\quad{\text{with probability } }{\rho}({\boldsymbol{x} },{\boldsymbol{w} }),\\ {\boldsymbol{x} }\quad{\text{with probability } }{1} - {\rho}({\boldsymbol{x} },{\boldsymbol{w} }).\end{array}\end{cases} \tag{8} \end{equation*} $$
因此 y 的条件概率密度是两个质点的概率密度函数的混合,一个集中在 w, 权重为 ρ(x, w); 另一个集中在 x, 权重为 1 − ρ(x, w), 即
δ(y − w)ρ(x, w) + δ(y − x)[1 − ρ(x, w)].
δ(⋅) 是 Dirac delta 函数,当且仅当 A 包含 $\bf{0}$ 的时候有 ∫Aδ(x′)dx′ = 1, 其他时候 ∫Aδ(x′)dx′ = 0.
其积分即 x 通过 q(⋅ | x) 转移到 y 的条件概率密度,即
$$ \begin{align*}{K}({\boldsymbol{y} }\,{\vert}\,{\boldsymbol{x} }) & = {\int}\left\{ {\delta}({\boldsymbol{y} } - {\boldsymbol{w} }){\rho}({\boldsymbol{x} },{\boldsymbol{w} }) + {\delta}({\boldsymbol{y} } - {\boldsymbol{x} })({1} - {\rho}({\boldsymbol{x} },{\boldsymbol{w} })\right\}\times{q}({\boldsymbol{w} }\,{\vert}\,{\boldsymbol{x} }){d}{\boldsymbol{w} }\\ & = {\rho}({\boldsymbol{x} },{\boldsymbol{y} }){q}({\boldsymbol{y} }\,{\vert}\,{\boldsymbol{x} }) + {\delta}({\boldsymbol{y} } - {\boldsymbol{x} })\left({1} - {r}({\boldsymbol{x} })\right), \tag{10} \end{align*} $$ 其中 r(x) = ∫ρ(x, w)q(w | x)dw.
- 右边的第一个乘积表示当候选值被接受时的转移概率(即y = w)),第二个乘积表示在拒绝候选值 w 的情况下从 x 到 x 的转移概率。因此,转移概率密度既有连续又有离散部分,并且对于每个集合 A 满足 ∫AK(y | x)dy = ∫Aρ(x, y)q(y | x)dy + IA(x)[1 − r(x)], 其中 IA 是 A 的指示函数,由下式给出 $$ \begin{equation*}{I}_{A}({\boldsymbol{x} }) = \mathop{\int}\nolimits_{A}{\delta}({\boldsymbol{y} } - {\boldsymbol{x} }){d}{\boldsymbol{y} } = \begin{cases}\begin{array}{ll}{1,}&{\text{if } }{\boldsymbol{x} }\,\in\,{A},\\{0,}&{\text{if } }{\boldsymbol{x} } \notin {A}.\end{array}\end{cases} \tag{13} \end{equation*} $$
可以看出,通过将(12)中的 A 取为 ${\cal{X} }$,K(⋅ | x) 对每个 ${\boldsymbol{x} }\,\in\,{\cal{X} }$ 积分为 1。即当 ${A} = {\cal{X} }$ 时,(12) 右边的积分 (关于 y) 的公式变为 r(x) 并且指标 ${I}_{\cal{X} }({\boldsymbol{x} }) = {1}$,因此 ∫K(y | x)dy = 1。
收敛性
如果马尔可夫链的概率是 k-步转移概率的极限,则马尔可夫链的概率密度 p̃(⋅) 是平稳的,而与马尔可夫链的起点无关,也就是说,如果对于每个独立于集合 A 的 x0 有 P(Xk ∈ A | X0 = x0) → ∫Ap̃(y)dy. 此外,如果马尔可夫链的转移核是不可约的,则马尔可夫链的平稳密度是唯一的。因此,如果 M-H 算法收敛(在适当的意义上)并且其核是不可约的,那么极限分布就是目标分布。因此,在为 M-H 算法选择提议密度时,该密度必须是相关转换核不可约的密度。下图说明了马尔可夫链的收敛性、不可约性和稳态密度之间的关系。
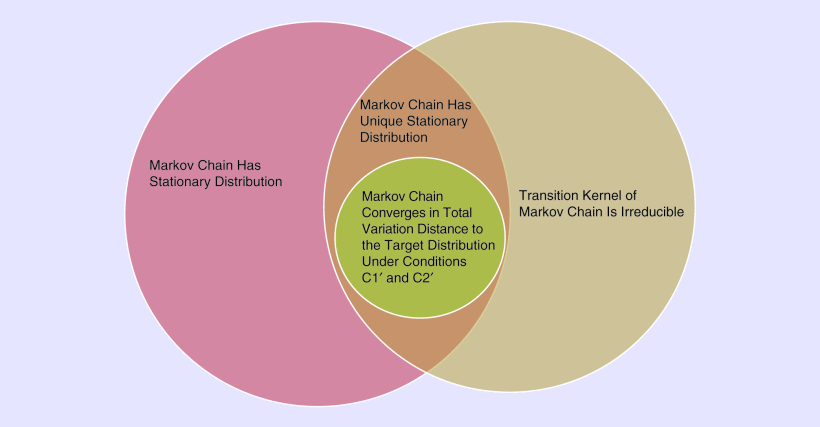
图:平稳性、收敛性和不可约性之间关系的说明。如果马尔可夫链不可约且具有平稳分布,则马尔可夫链具有唯一的平稳分布。目标分布是 Metropolis-Hastings 马尔可夫链的平稳分布。如果条件 (C1’) 和 (C2’) 成立,则 k 步转移概率收敛于到目标分布的总变化距离,其中初始状态是 S 中的任意点.
实验
- 目标分布:标准柯西分布
- 提议分布:标准正态分布
- 马尔可夫链长度:10000
- 老化期(burn-in): 1000
实验过程
导入所需的库
1 | import numpy as np |
实现 M-H 算法
1 | def Metropolis(step, target, proposal): |
输出结果为:
1 | reject probablity: 0.22671 |
即拒绝概率为 22.67%, 是合理的,将结果进行可视化
1 | def DrawDistribution(x, burn, target): |
如下图所示
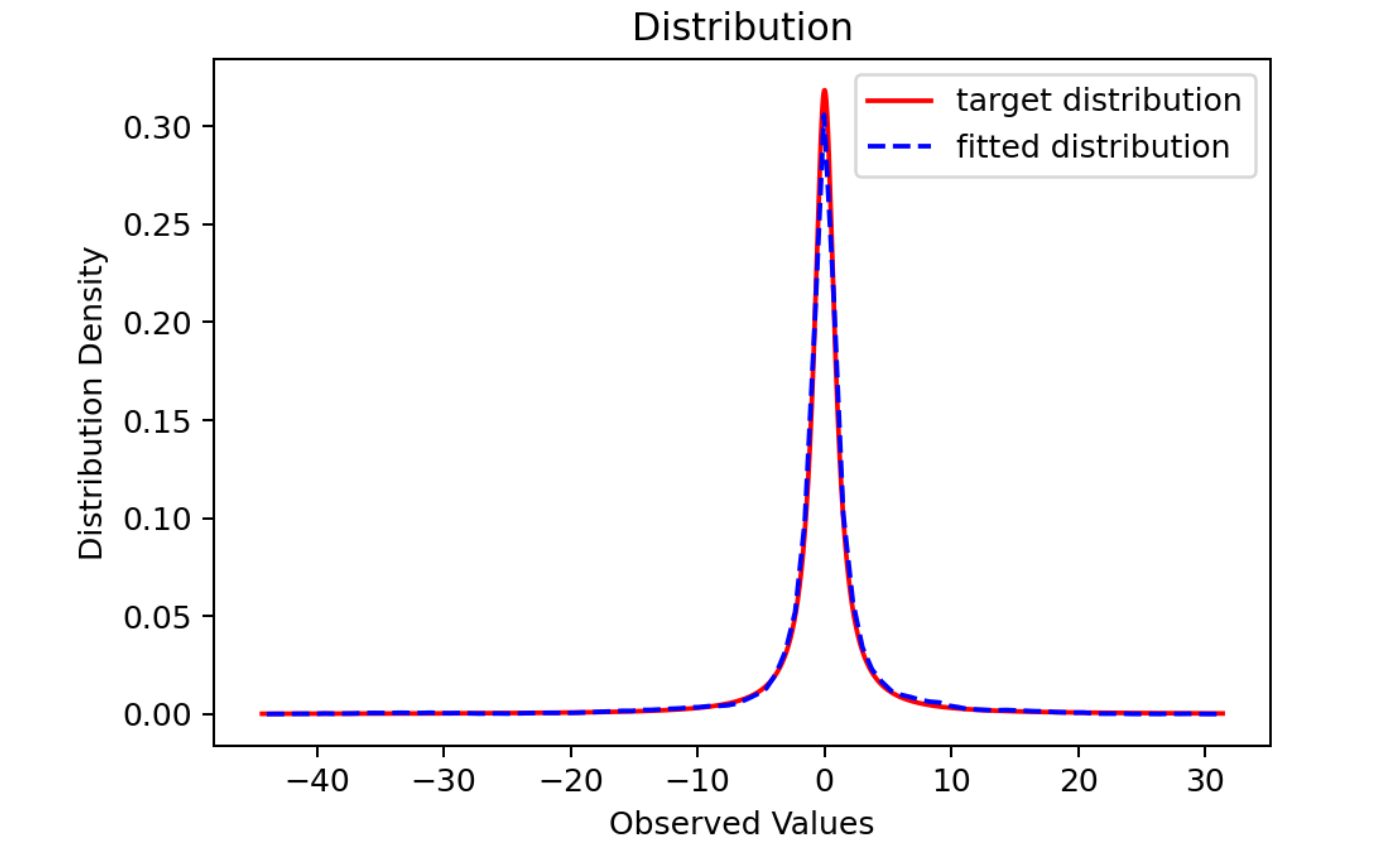
可见采样结果与目标分布基本一致
参考资料
[1] 蒙特卡洛方法:https://en.wikipedia.org/wiki/Monte_Carlo_method
[2] 马尔可夫链:https://en.wikipedia.org/wiki/Markov_chain
[3] S. D. Hill and J. C. Spall, “Stationarity and Convergence of the
Metropolis-Hastings Algorithm: Insights into Theoretical Aspects,” in
IEEE Control Systems Magazine, vol. 39, no. 1, pp. 56-67, Feb. 2019,
doi: 10.1109/MCS.2018.2876959.
[4] https://zhuanlan.zhihu.com/p/143016455
[5] https://zhuanlan.zhihu.com/p/37121528
[6] G. O. Roberts and J. S. Rosenthal , “Optimal scaling for various
Metropolis-Hastings algorithms,” Statist. Sci, vol. 16, no. 4,
pp. 351–367, 2001. doi: 10.1214/ss/1015346320.
[7] Robert, Christian; Casella, George (2004). Monte Carlo Statistical
Methods. Springer. ISBN 978-0387212395.