前言
C++ 开发项目的学习笔记,来自牛客,源视频地址:https://www.nowcoder.com/study/live/504.
Linux系统编程入门
Linux 开发环境搭建
很基础的内容,以前已经配过啦,就不赘述了,目前我使用的环境是:
- 本地操作环境:Window 10
- Linux: Ubuntu 18.04 (实验室的 Linux 服务器)
- IDE:VSCode,本地编程,使用 SFTP 插件同步到服务器
- SSH 远程:MobaXterm
- SFTP 文件传输:FileZilla
GCC
简介
- GCC 原名为GNU C语言编译器(GNU C Compiler)
- GCC(GNU Compiler Collection,GNU编译器套件)是由GNU 开发的编程语言译器。GNU 编译器套件包括C、C++、Objective-C、Java、Ada 和Go 语言前端,也包括了这些语言的库(如libstdc++,libgcj等)
- GCC 不仅支持C 的许多“方言”,也可以区别不同的C
语言标准;可以使用命令行选项来控制编译器在翻译源代码时应该遵循哪个C
标准。例如,当使用命令行参数
-std=c99启动GCC 时,编译器支持C99 标准。 - 安装命令
sudo apt install gcc g++(版本> 4.8.5) - 查看版本:
gcc/g++ -v/--version
工作流程

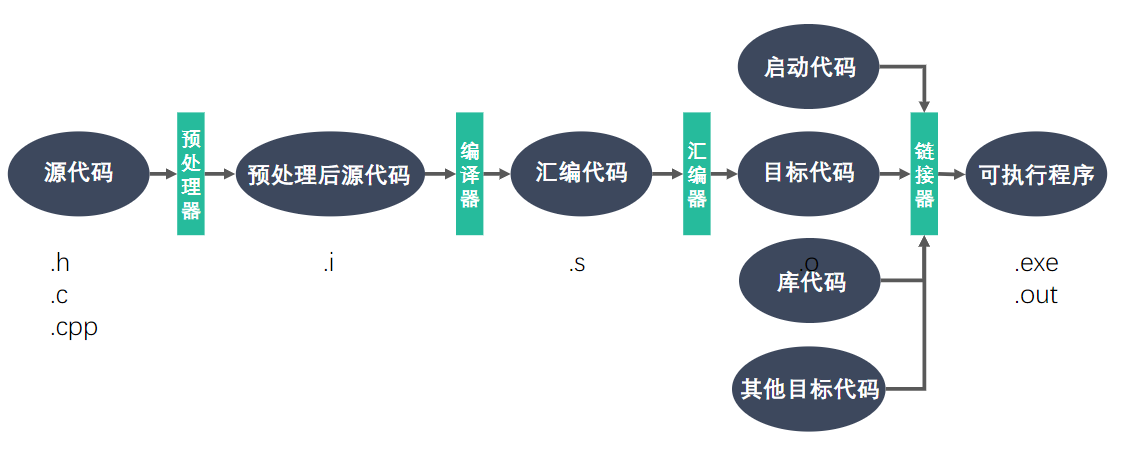
- 预处理包括:将头文件添加的目标文件,删掉注释,宏替换等,命令为
gcc hello.c -E -o hello.i - 编译器将预处理后的代码编译为汇编代码,命令为
gcc hello.i -S -o hello.s - 汇编代码将汇编代码汇编为机器可以执行的二进制文件,命令为
gcc hello.s -c -o hello.o
gcc 与 g++ 的区别
- gcc 和g++都是GNU(组织)的一个编译器。
- 误区一:gcc 只能编译c 代码,g++ 只能编译c++
代码。两者都可以,请注意:
- 后缀为.c 的,gcc 把它当作是C 程序,而g++ 当作是c++ 程序
- 后缀为.cpp 的,两者都会认为是C++ 程序,C++ 的语法规则更加严谨一些
- 编译阶段,g++ 会调用gcc,对于C++ 代码,两者是等价的,但是因为gcc命令不能自动和C++ 程序使用的库联接,所以通常用g++ 来完成链接,为了统一起见,干脆编译/链接统统用g++ 了,这就给人一种错觉,好像cpp 程序只能用g++ 似的
- 误区二:gcc 不会定义
__cplusplus宏,而 g++ 会- 实际上,这个宏只是标志着编译器将会把代码按 C 还是 C++ 语法来解释
- 如上所述,如果后缀为.c,并且采用gcc 编译器,则该宏就是未定义的,否则,就是已定义
- 误区三:编译只能用gcc,链接只能用g++
- 严格来说,这句话不算错误,但是它混淆了概念,应该这样说:编译可以用gcc/g++,而链接可以用g++
或者
gcc -lstdc++。 - gcc 命令不能自动和 C++ 程序使用的库联接,所以通常使用 g++ 来完成联接。但在编译阶段,g++ 会自动调用 gcc,二者等价
- 严格来说,这句话不算错误,但是它混淆了概念,应该这样说:编译可以用gcc/g++,而链接可以用g++
或者
参数表
| 选项 | 说明 |
|---|---|
| -E | 预处理指定的源文件,不进行编译 |
| -S | 编译指定的源文件,但是不进行汇编 |
| -c | 编译、汇编指定的源文件,但是不进行链接 |
| -o | 将文件file2 编译成可执行文件file1 |
| -I | 指定include 包含文件的搜索目录 |
| -g | 在编译的时候,生成调试信息,该程序可以被调试器调试 |
| -D | 在程序编译的时候,指定一个宏 |
| -w | 不生成任何警告信息 |
| -Wall | 生成所有警告信息 |
| -On | n的取值范围:0~3。编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高 |
| -l | 在程序编译的时候,指定使用的库 |
| -L | 指定编译的时候,搜索的库的路径 |
| -fPIC/-fpic | 生成与位置无关的代码 |
| -shared | 生成共享目标文件,通常用在建立共享库时 |
| -std | 指定C方言,如:-std=c99,gcc默认的方言是GNU C |
静态库
简介
- 库文件是计算机上的一类文件,可以简单的把库文件看成一种代码仓库,它提供给使用者一些可以直接拿来用的变量、函数或类
- 库是特殊的一种程序,编写库的程序和编写一般的程序区别不大,只是库不能单独运行
- 库文件有两种,静态库和动态库(共享库),区别是:静态库在程序的链接阶段被复制到了程序中;动态库在链接阶段没有被复制到程序中,而是程序在运行时由系统动态加载到内存中供程序调用
- 库的好处:1.代码保密2.方便部署和分发
命名规则
- Linux: lib(前缀)+库名字+.a(后缀)
- windows: libxxx.lib
制作方法
- gcc 获得
.o文件 - 使用 ar 工具 (archive)
打包:
ar rcs libxxx.a xxx1.o xxx2.o- r –将文件插入备存文件中
- c –建立备存文件
- s –索引
静态库的使用示例:
文件树:
1 | ├── include |
- 使用
gcc -c add.c sub.c mult.c div.c -I ../include/获得.o文件 - 使用
ar rcs libcalc.a add.o div.o mult.o sub.o获得libcalc.a库文件,移动到 lib 目录下 - 编译
main.c:gcc main.c -o main.a -I include/ -l calc -L ./lib/
动态库
命名规则
- Linux: lib(前缀)+库名字+.so(后缀)
- windows: libxxx.dll
制作方法
- gcc 获得
.o文件,得到与位置无关的代码:gcc -c -fpic a.c b.c即添加-fpic参数 - 获得动态库:
gcc -shared a.o b.o -o libcalc.so
动态库的使用示例:
文件树:
1 | ├── include |
- 使用
gcc -c -fpic add.c sub.c mult.c div.c -I ../include/获得.o文件 - 使用
gcc -shared *.o -o libcalc.so获得libcalc.so库文件,移动到 lib 目录下 - 编译
main.c:gcc main.c -o main.aa -I include/ -l calc -L ./lib/
但此时如果直接
运行会报错:./main.aa: error while loading shared libraries: libcalc.so: cannot open shared object file: No such file or directory
即无法找到动态库
动态库的原理
- 静态库:GCC 进行链接时,会把静态库中代码打包到可执行程序中
- 动态库:GCC 进行链接时,动态库的代码不会被打包到可执行程序中
- 程序启动之后,动态库会被动态加载到内存中,通过ldd(list dynamic dependencies)命令检查动态库依赖关系
- 如何定位共享库文件呢?当系统加载可执行代码时候,能够知道其所依赖的库的名字,但是还需要知道绝对路径。此时就需要系统的动态载入器来获取该绝对路径。对于elf格式的可执行程序,是由ld-linux.so来完成的,它先后搜索elf文件的DT_RPATH段——> 环境变量LD_LIBRARY_PATH ——> /etc/ld.so.cache文件列表——> /lib/,/usr/lib目录找到库文件后将其载入内存。
使用 ldd 分析可执行文件 main.aa 得到
1 | linux-vdso.so.1 (0x00007ffd3cd51000) |
解决方法是
- 将动态库路径添加到环境变量
- 只是暂时性添加到环境变量:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/user/webserver/library/lib, 最后的是动态库的绝对路径,该方法关闭 SSH 后就失效了 - 用户级别,将上述代码添加到
.bashrc,重启或刷新(source ~/.bashrc) - 系统级别,将上述代码添加到
/etc/profile中,重启或刷新 - 可以使用
env查看
- 只是暂时性添加到环境变量:
- 添加到
/etc/ld.so.cache文件列表/etc/ld.so.cache是一个二进制文件不能直接修改,需要将绝对路径添加到/etc/ld.so.conf中,再刷新ldconfig即可
- 放到/lib/,/usr/lib目录
- 但不推荐这种方法,因为这两个目标本身有很多库文件,不推荐将自己的库文件放到一起
MakeFile
MakeFile简介
- 一个工程中的源文件不计其数,其按类型、功能、模块分别放在若干个目录中,Makefile 文件定义了一系列的规则来指定哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,因为Makefile 文件就像一个Shell 脚本一样,也可以执行操作系统的命令
- Makefile 带来的好处就是“自动化编译”,一旦写好,只需要一个make 命令,整个工程完全自动编译,极大的提高了软件开发的效率。make 是一个命令工具,是一个解释Makefile 文件中指令的命令工具,一般来说,大多数的IDE 都有这个命令,比如Delphi 的make,Visual C++ 的nmake,Linux 下GNU 的make。
文件命名:必须为 makefile 或 Makefile
Makefile 基本规则
1 | 注释用 #标记 |
例如:
1 | main.a:sub.c add.c mult.c div.c main.c |
执行 make 即可运行 Makefile
- 一个Makefile 文件中可以有一个或者多个规则
- 目标:最终要生成的文件(伪目标除外)
- 依赖:生成目标所需要的文件或是目标
- 命令:通过执行命令对依赖操作生成目标(命令前必须Tab 缩进)
- Makefile 中的其它规则一般都是为第一条规则服务的(与第一条规则无关的不会执行)
- 命令在执行之前,需要先检查规则中的依赖是否存在
- 如果存在,执行命令
- 如果不存在,向下检查其它的规则,检查有没有一个规则是用来生成这个依赖的,如果找到了,则执行该规则中的命令
- 检测更新,在执行规则中的命令时,会比较目标和依赖文件的时间
- 如果依赖的时间比目标的时间晚,需要重新生成目标
- 如果依赖的时间比目标的时间早,目标不需要更新,对应规则中的命令不需要被执行
关于依赖和更新的示例:
1 | main.a:sub.o add.o mult.o div.o main.o |
变量和函数
- 自定义变量
- makefile 没有数据结构,所有变量都可以视为字符串
- 语法:
变量名=变量值如var=hello, 引用变量$(var)
- 一些预定义变量
AR: 归档维护程序的名称,默认值为arCC: C 编译器的名称,默认值为ccCXX: C++ 编译器的名称,默认值为g++
- 自动变量(只能再规则命令中使用)
$@: 目标的完整名称$<: 第一个依赖文件的名称$^: 所有的依赖文件
- 模式匹配
%.o:%.c%: 通配符,匹配一个字符串- 两个
%匹配的是同一个字符串
- 函数
$(wildcard PATTERN...)- 功能:获取指定目录下指定类型的文件列表
- 参数:PATTERN 指的是某个或多个目录下的对应的某种类型的文件,如果有多个目录,一般使用空格间隔
- 返回:得到的若干个文件的文件列表,文件名之间使用空格间隔
- 示例:
$(wildcard *.c ./sub/*.c) $(patsubst <pattern>,<replacement>,<text>)- 功能:查找
<text>中的单词(单词以“空格”、“Tab”或“回车”“换行”分隔)是否符合模式<pattern>,如果匹配的话,则以<replacement>替换。 <pattern>可以包括通配符%,表示任意长度的字串。如果<replacement>中也包含%,那么,<replacement>中的这个%将是<pattern>中的那个%所代表的字串。(可以用\来转义,以\%来表示真实含义的%字符)- 返回:函数返回被替换过后的字符串
- 示例:
$(patsubst %.c, %.o, x.c bar.c)
改写过的示例
1 | src=$(wildcard ./*.c) |
正常执行 make 并不会执行
clean,需要指定:make clean
GDB调试
GDB简介
- GDB 是由GNU 软件系统社区提供的调试工具,同GCC 配套组成了一套完整的开发环境,GDB 是Linux 和许多类Unix 系统中的标准开发环境。
- 一般来说,GDB 主要帮助你完成下面四个方面的功能:
- 启动程序,可以按照自定义的要求随心所欲的运行程序
- 可让被调试的程序在所指定的调置的断点处停住(断点可以是条件表达式)
- 当程序被停住时,可以检查此时程序中所发生的事
- 可以改变程序,将一个BUG 产生的影响修正从而测试其他BUG
- 通常,在为调试而编译时,我们会()关掉编译器的优化选项(
-O),并打开调试选项(-g)。另外,-Wall在尽量不影响程序行为的情况下选项打开所有warning,也可以发现许多问题,避免一些不必要的BUG。 gcc -g -Wall program.c -o program-g选项的作用是在可执行文件中加入源代码的信息,比如可执行文件中第几条机器指令对应源代码的第几行,但并不是把整个源文件嵌入到可执行文件中,所以在调试时必须保证gdb 能找到源文件
GDB命令
基本命令
| 命令 | 代码 |
|---|---|
| 启动 | gdb 可执行程序 |
| 退出 | quit |
| 给程序设置参数 | set args 10 20 |
| 获取设置参数 | show args |
| GDB 使用帮助 | help |
| 查看当前文件代码 | list/l (从默认位置显示) |
| list/l 行号(从指定的行显示) | |
| list/l 函数名(从指定的函数显示) | |
| 查看非当前文件代码 | list/l 文件名:行号 |
| list/l 文件名:函数名 | |
| 查看显示的行数 | show list/listsize |
| 设置显示的行数 | set list/listsize 行数 |
断点操作
| 命令 | 代码 |
|---|---|
| 设置断点 | b/break 行号 |
| b/break 函数名 | |
| b/break 文件名:行号 | |
| b/break 文件名:函数 | |
| 查看断点 | i/info b/break |
| 删除断点 | d/del/delete 断点编号 |
| 设置断点无效 | dis/disable 断点编号 |
| 设置断点生效 | ena/enable 断点编号 |
| 设置条件断点(一般用在循环的位置) | b/break 10 if i==5 |
调试命令
| 命令 | 代码 |
|---|---|
| 运行GDB程序 | start(程序停在第一行) |
| run(遇到断点才停) | |
| 继续运行,到下一个断点停 | c/continue |
| 向下执行一行代码(不会进入函数体) | n/next |
| 变量操作 | p/print 变量名(打印变量值) |
| ptype 变量名(打印变量类型) | |
| 向下单步调试(遇到函数进入函数体) | s/step |
| finish(跳出函数体) | |
| 自动变量操作 | display 变量名(自动打印指定变量的值) |
| i/info display | |
| undisplay 编号 | |
| 其它操作 | set var 变量名=变量值(循环中用的较多) |
| until (跳出循环) |
文件IO
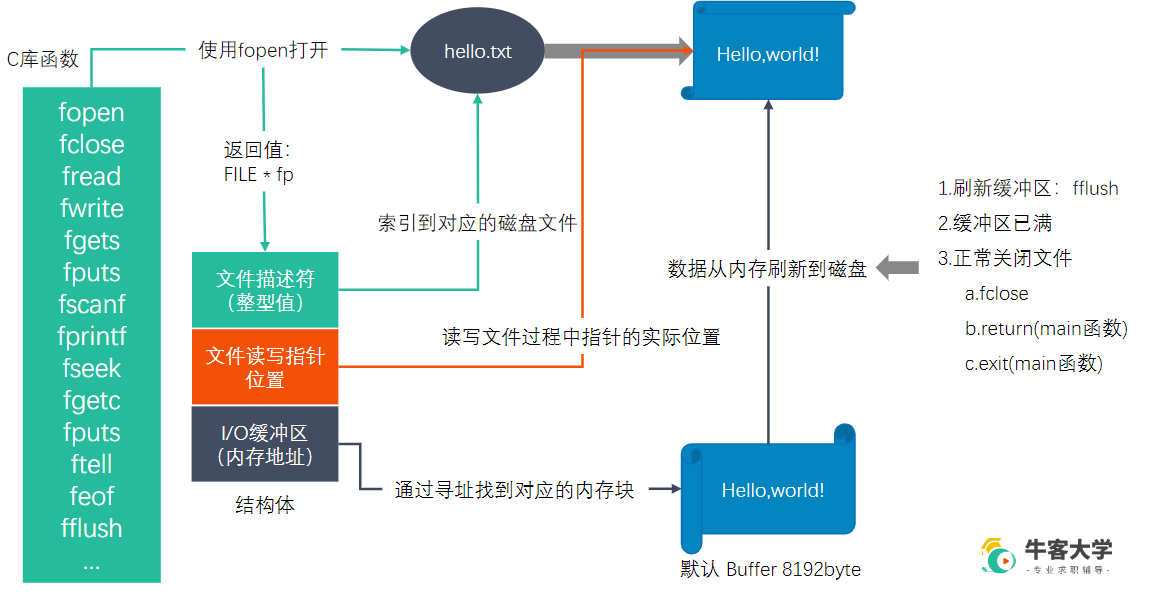
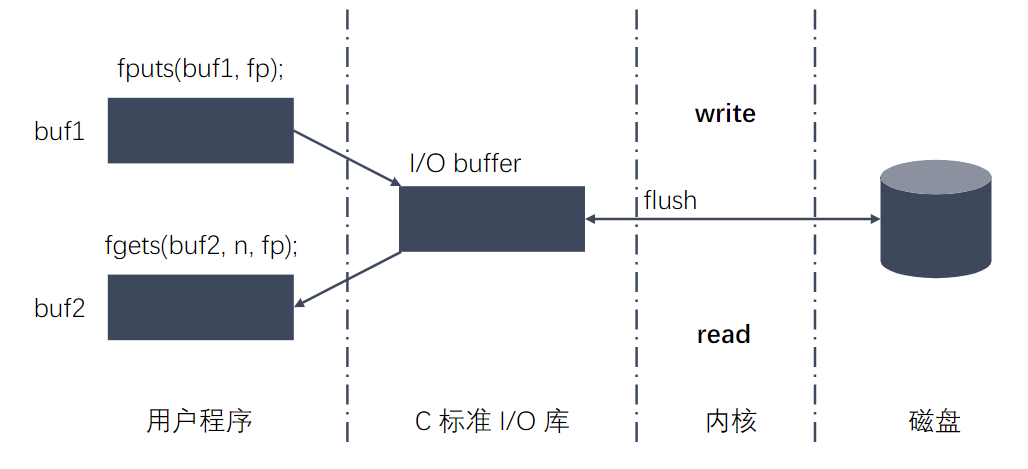
标准C库与Linux的 IO 函数的区别
- 标准C库的函数是跨平台的,是通过调用不同平台的系统API实现的
- 标准C库的IO函数有缓冲区,效率更高一些
虚拟地址空间
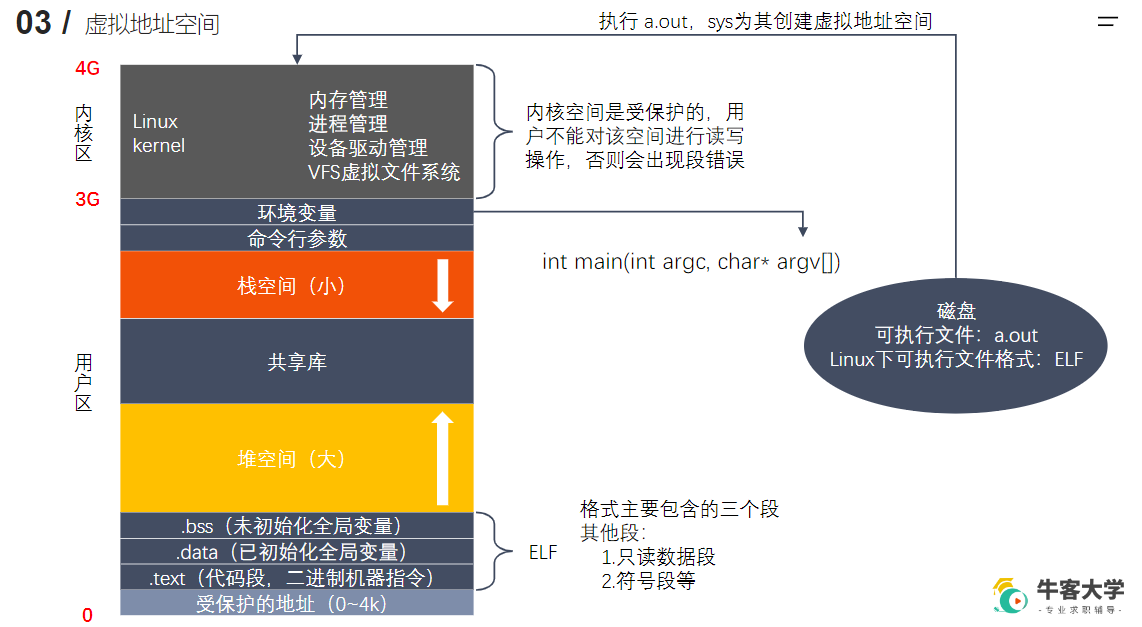
通过 MMU 将虚拟地址空间映射到物理地址空间
文件描述符
文件描述符保存在Linux内核区
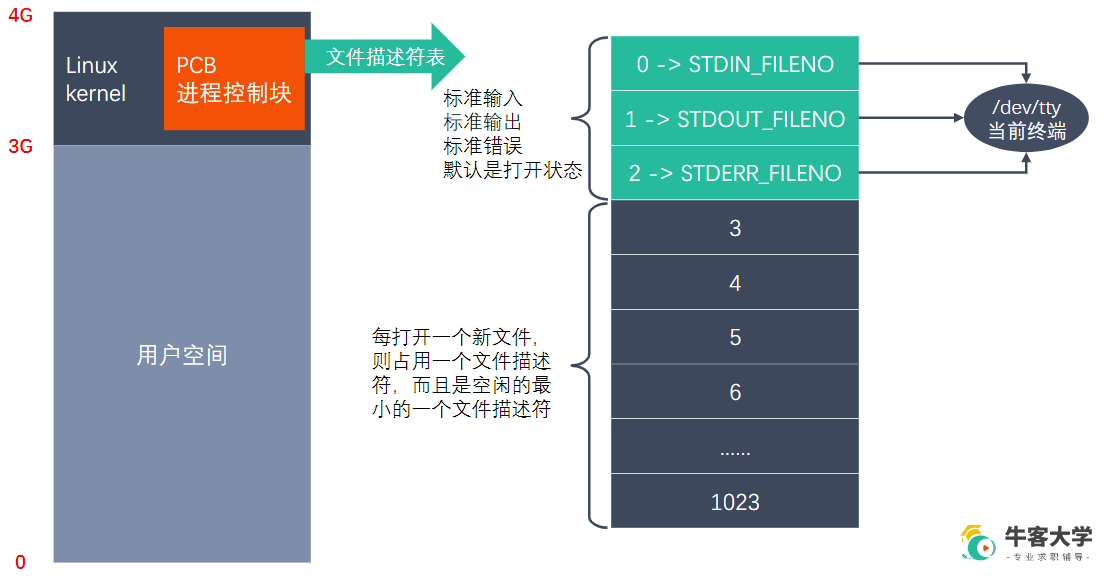
PCB 中有个文件描述符表(数组),前三个固定是标准输入输出标准错误,对应当前终端。
文件可以重复打开,文件描述符不一样
Linux系统IO函数
Linux的系统API函数可以通过 man 2 函数名
查看说明文档,man 3 函数名 查看标准 C 库函数说明文档
open 函数:打开文件
1 | /* |
open 函数:创建文件,与打开文件不同的是添加“不存在则创建”的
flags.
1 | /* |
umask 的值可以直接在linux终端输入 umask
查看
读写函数:read, write
1 | /* |
lseek 函数,用于移动文件指针
1 | /* |
stat 函数:获取文件属性,与终端使用 stat 效果类似
1 | /* |
stat 结构体定义
1 | struct stat { |
st_mode 变量
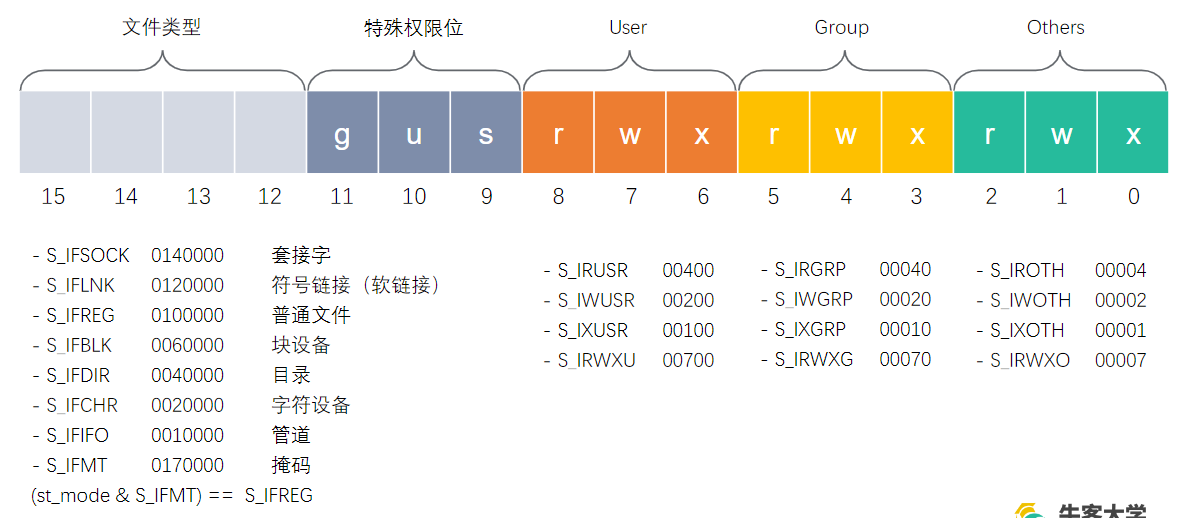
模拟实现 ls -l 命令的示例
1 |
|
文件属性操作函数
access
1 | /* |
chmod
1 | /* |
chown: 修改文件所有者和所在组
1 | int chown(const char *path, uid_t owner, gid_t group); |
使用 man 2 chown 可以查看帮助文档,所有者 ID 与所在组 ID
可以查看 /etc/passwd 文件或
/etc/group,亦可以在终端 id 用户名 查看
truncate
1 | /* |
目录操作函数
都是常用操作了,作用显而易见
1 | /* |
目录遍历函数
1 | /* |
dirent 结构体和 d_type(宏值)

文件描述符操作函数
1 | /* |
Linux多进程开发
进程概述
程序是包含一系列信息的文件,这些信息描述了如何在运行时创建一个进程:
- 二进制格式标识:每个程序文件都包含用于描述可执行文件格式的元信息。内核利用此信息来解释文件中的其他信息。(ELF可执行连接格式)
- 机器语言指令:对程序算法进行编码。
- 程序入口地址:标识程序开始执行时的起始指令位置。
- 数据:程序文件包含的变量初始值和程序使用的字面量值(比如字符串)。
- 符号表及重定位表:描述程序中函数和变量的位置及名称。这些表格有多重用途,其中包括调试和运行时的符号解析(动态链接)。
- 共享库和动态链接信息:程序文件所包含的一些字段,列出了程序运行时需要使用的共享库,以及加载共享库的动态连接器的路径名。
- 其他信息:程序文件还包含许多其他信息,用以描述如何创建进程。
- 进程是正在运行的程序的实例。是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元,在传统的操作系统中,进程既是基本的分配单元,也是基本的执行单元。
- 可以用一个程序来创建多个进程,进程是由内核定义的抽象实体,并为该实体分配用以执行程序的各项系统资源。从内核的角度看,进程由用户内存空间和一系列内核数据结构组成,其中用户内存空间包含了程序代码及代码所使用的变量,而内核数据结构则用于维护进程状态信息。记录在内核数据结构中的信息包括许多与进程相关的标识号(IDs)、虚拟内存表、打开文件的描述符表、信号传递及处理的有关信息、进程资源使用及限制、当前工作目录和大量的其他信息。
单道与多道程序
- 单道程序,即在计算机内存中只允许一个的程序运行。
- 多道程序设计技术是在计算机内存中同时存放几道相互独立的程序,使它们在管理程序控制下,相互穿插运行,两个或两个以上程序在计算机系统中同处于开始到结束之间的状态, 这些程序共享计算机系统资源。引入多道程序设计技术的根本目的是为了提高 CPU 的利用率。
- 对于一个单 CPU 系统来说,程序同时处于运行状态只是一种宏观上的概念,他们虽然都已经开始运行,但就微观而言,任意时刻,CPU 上运行的程序只有一个。
- 在多道程序设计模型中,多个进程轮流使用 CPU。而当下常见 CPU 为纳秒级,1秒可以执行大约 10 亿条指令。由于人眼的反应速度是毫秒级,所以看似同时在运行。
时间片
- 时间片(timeslice)又称为“量子(quantum)”或“处理器片(processor slice)”是操作系统分配给每个正在运行的进程微观上的一段 CPU 时间。事实上,虽然一台计算机通常可能有多个 CPU,但是同一个 CPU 永远不可能真正地同时运行多个任务。在只考虑一个 CPU 的情况下,这些进程“看起来像”同时运行的,实则是轮番穿插地运行,由于时间片通常很短(在 Linux 上为 5ms-800ms),用户不会感觉到。
- 时间片由操作系统内核的调度程序分配给每个进程。首先,内核会给每个进程分配相等的初始时间片,然后每个进程轮番地执行相应的时间,当所有进程都处于时间片耗尽的状态时,内核会重新为每个进程计算并分配时间片,如此往复。
并发与并行
- 并行(parallel):指在同一时刻,有多条指令在多个处理器上同时执行。
- 并发(concurrency):指在同一时刻只能有一条指令执行,但多个进程指令被快速的轮换执行,使得在宏观上具有多个进程同时执行的效果,但在微观上并不是同时执行的,只是把时间分成若干段,使多个进程快速交替的执行。
进程控制块(PCB)
- 为了管理进程,内核必须对每个进程所做的事情进行清楚的描述。内核为每个进程分配一个 PCB(Processing Control Block)进程控制块,维护进程相关的信息,Linux 内核的进程控制块是 task_struct 结构体。
- 在
/usr/src/linux-headers-xxx/include/linux/sched.h文件中可以查看 struct task_struct 结构体定义。其内部成员有很多,我们只需要掌握以下部分即可:- 进程id:系统中每个进程有唯一的 id,用 pid_t 类型表示,其实就是一个非负整数
- 进程的状态:有就绪、运行、挂起、停止等状态
- 进程切换时需要保存和恢复的一些CPU寄存器
- 描述虚拟地址空间的信息
- 描述控制终端的信息
- 当前工作目录(Current Working Directory)
- umask 掩码
- 文件描述符表,包含很多指向 file 结构体的指针
- 和信号相关的信息
- 用户 id 和组 id
- 会话(Session)和进程组
- 进程可以使用的资源上限(Resource Limit)
- 可以在终端中使用
ulimit -a查看可使用资源上限
- 可以在终端中使用
进程状态转换
进程状态
进程状态反映进程执行过程的变化。这些状态随着进程的执行和外界条件的变化而转换。在三态模型中,进程状态分为三个基本状态,即就绪态,运行态,阻塞态。在五态模型中,进程分为新建态、就绪态,运行态,阻塞态,终止态。
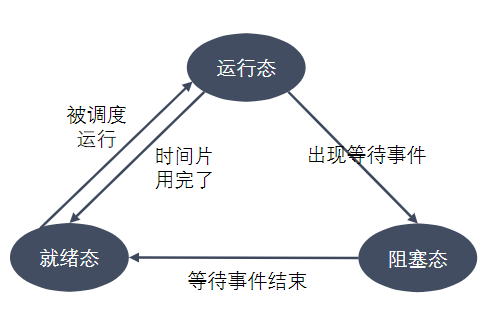
- 运行态:进程占有处理器正在运行
- 就绪态:进程具备运行条件,等待系统分配处理器以便运行。当进程已分配到除CPU以外的所有必要资源后,只要再获得CPU,便可立即执行。在一个系统中处于就绪状态的进程可能有多个,通常将它们排成一个队列,称为就绪队列
- 阻塞态:又称为等待(wait)态或睡眠(sleep)态,指进程不具备运行条件,正在等待某个事件的完成
- 新建态:进程刚被创建时的状态,尚未进入就绪队列
- 终止态:进程完成任务到达正常结束点,或出现无法克服的错误而异常终止,或被操作系统及有终止权的进程所终止时所处的状态。进入终止态的进程以后不再执行,但依然保留在操作系统中等待善后。一旦其他进程完成了对终止态进程的信息抽取之后,操作系统将删除该进程。
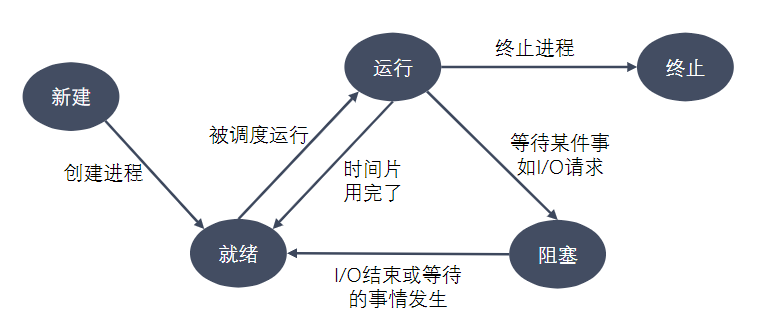
查看进程
命令:ps aux 或 ps ajx
- a:显示终端上的所有进程,包括其他用户的进程
- u:显示进程的详细信息
- x:显示没有控制终端的进程
- j:列出与作业控制相关的信息
进程表中 STAT 参数的含义
| SRAT | 意义 |
|---|---|
| D | 不可中断Uninterruptible(usually IO) |
| R | 正在运行,或在队列中的进程 |
| S(大写) | 处于休眠状态 |
| T | 停止或被追踪 |
| Z | 僵尸进程 |
| W | 进入内存交换(从内核2.6开始无效) |
| X | 死掉的进程 |
| < | 高优先级 |
| N | 低优先级 |
| s | 包含子进程 |
| + | 位于前台的进程组 |
更高级一些的显示进程动态:top
- 可以在使用top 命令时加上-d来指定显示信息更新的时间间隔,在top
命令执行后,可以按以下按键对显示的结果进行排序:
- M 根据内存使用量排序
- P 根据CPU 占有率排序
- T 根据进程运行时间长短排序
- U 根据用户名来筛选进程
- K 输入指定的PID 杀死进程
相关函数
- 杀死进程
kill [-signal] pidkill –l列出所有信号kill –SIGKILL 进程IDkill -9 进程IDkillall name根据进程名杀死进程
- 每个进程都由进程号来标识,其类型为pid_t(整型),进程号的范围:0~32767。进程号总是唯一的,但可以重用。当一个进程终止后,其进程号就可以再次使用。
- 任何进程(除init 进程)都是由另一个进程创建,该进程称为被创建进程的父进程,对应的进程号称为父进程号(PPID)。
- 进程组是一个或多个进程的集合。他们之间相互关联,进程组可以接收同一终端的各种信号,关联的进程有一个进程组号(PGID)。默认情况下,当前的进程号会当做当前的进程组号。
- 进程号和进程组相关函数
pid_t getpid(void);pid_t getppid(void);pid_t getpgid(pid_t pid);